개념·용어
-
 Deployment (배포·배달 방식) 변화
Deployment (배포·배달 방식) 변화앱 배포 환경의 변화에 대한 주요 개념으로는 물리적 자원과 추상화된 논리적 객체, Host OS와 Guest OS, 이미지와 컨테이너, 오케스트레이션, 그리고 Kubernetes가 포함된다. Kubernetes는 컨테이너의 배포, 확장 및 관리를 자동화하는 오픈소스 플랫폼으로, Pod, Service, Deployment와 같은 객체를 통해 효율적으로 관리한다.
- LLM 한국문화 특화 모형 개발법
LLM 개발을 위해 고품질 한국어 코퍼스의 중요성이 강조된다. 사전학습, 정렬 튜닝, 추론 단계가 필요하며, 한국어 특화 모델의 성능 향상을 위해 구조화된 데이터와 어휘 조정이 필수적이다. 다양한 한국어 문서를 활용한 재학습과 정제된 질문-응답 쌍이 요구된다.
- AI Wrapper 설계 기초
LLM 기반 애플리케이션 개발은 기존 오픈소스 기술의 조합에 의존하며, LangChain과 RAG 기술을 활용하여 사용자 경험을 최적화하는 것이 중요하다. 애플리케이션은 유연한 계층 구조로 설계되어 각 계층이 특정 기능을 담당하며, PEFT, RAG, Agent 기술의 조합이 성공적인 앱 구축의 핵심 전략이다. LangChain은 다양한 모듈을 조율하여 복잡한 추론 흐름을 관리하며, 개발자의 경쟁력은 기술 모듈을 효과적으로 조합하고 최적화하는 능력에 있다.
- Dataset - DB와의 상호작용
CRUD 기능은 데이터베이스의 기본이며, REST API와 밀접하게 연결되어 있습니다. 트랜잭션은 원자성과 일관성을 보장하며, ACID 속성을 만족해야 합니다. 데이터 무결성을 위해 다양한 제약조건이 필요하며, 인덱싱은 검색 성능을 향상시킵니다. 정규화는 데이터 중복을 줄이고 구조적 일관성을 확보하는 데 중요하지만, 과도한 정규화는 성능 저하를 초래할 수 있습니다. 효율적인 데이터베이스 설계는 이러한 모든 요소들이 조화롭게 작동할 때 가능해집니다.
-
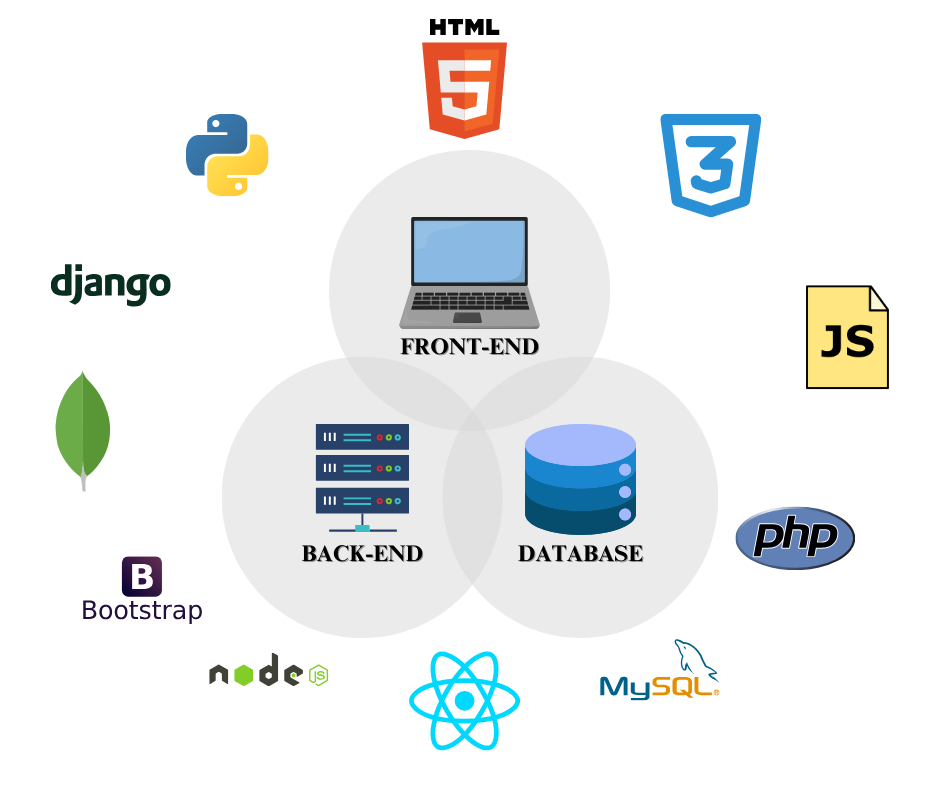 Web App Full Stack 개발 개요
Web App Full Stack 개발 개요웹 앱 개발은 백엔드 중심과 프론트엔드 중심 접근 방식으로 나뉘며, API를 통해 상호작용합니다. 주요 언어, 플랫폼, 프레임워크, 라이브러리를 소개하고, Next.js와 FastAPI의 통합 구조 및 프로젝트 디렉터리 구조를 설명합니다. 배포 방식은 Docker를 사용하여 통합 실행 설정을 제공합니다.
- Web App 관련 기술 용어 - 데이터 흐름으로 정리하기
웹 앱 개발에서 기술 용어보다 데이터 흐름의 이해가 중요하다. 입력, 처리, 출력을 명확히 구분하고 연결하여 설계해야 하며, Firebase 플랫폼을 활용하여 효율적인 개발이 가능하다. Tailwind CSS와 컴포넌트를 사용하여 사용자 인터페이스를 빠르게 구현할 수 있으며, 데이터 저장, 계산 로직, 표현 방식을 정확히 설계하는 것이 핵심이다.
-
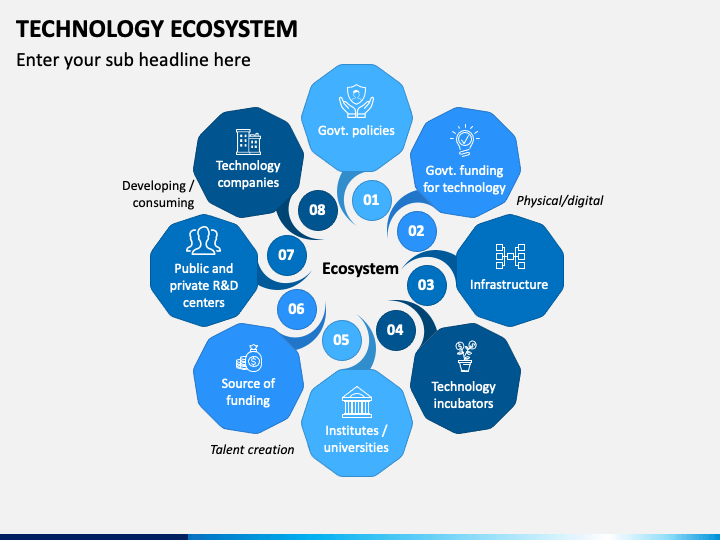 Ecosystem – Platform – Framework – Library
Ecosystem – Platform – Framework – Library생태계는 플랫폼, 프레임워크, 라이브러리, 커뮤니티, 도구 및 규제를 포함하는 전체 상호작용 시스템이다. 플랫폼은 앱과 서비스의 실행 기반을 제공하며, 프레임워크는 일관된 개발 구조를 제공하고, 라이브러리는 특정 기능을 가진 코드 묶음이다. 예시로는 NVIDIA GPU 생태계, Android 생태계, Python 생태계 등이 있다. 각 요소는 서로 연결되어 효율적인 개발과 실행을 지원한다.
- Web App Frontend 계층 구조
프론트엔드 계층 구조는 HTML, CSS, JavaScript를 포함하며, 각 계층의 주요 실습 도구로는 Live Server, Chrome DevTools, Tailwind 등이 있다. DOM 트리 구조 예시와 Tailwind CSS를 활용한 히어로 섹션 디자인 방법도 설명되어 있다. Tailwind CSS는 유틸리티 클래스 조합으로 빠른 디자인을 가능하게 하며, 반응형 디자인도 지원한다.
-
 OS Windows WSL2 파일 시스템
OS Windows WSL2 파일 시스템WSL2에서 Ubuntu는 대소문자를 구분하며, 파일 시스템 구조는 / 기반 단일 트리로 구성된다. Windows와의 파일 경로 연동이 가능하며, Ubuntu에서 Windows 파일에 접근할 때는 /mnt/ 경로를 사용한다. 실행 권한은 Ubuntu에서 별도로 관리되며, Windows는 확장자에 따라 실행 여부를 판단한다.
-
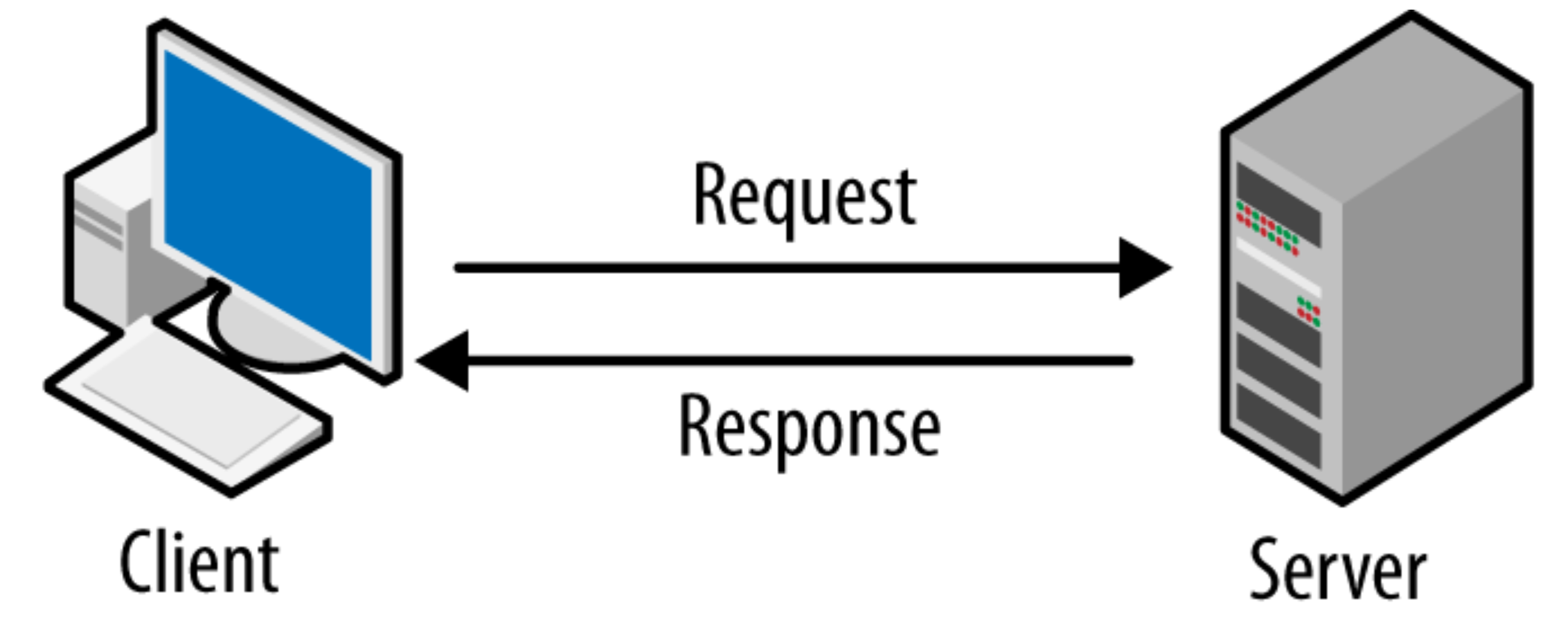 Data Flow. Client-Server 환경에서
Data Flow. Client-Server 환경에서클라이언트-서버 환경에서 SSH는 원격 서버의 Shell에 안전하게 접속하는 통신 프로토콜로, 사용자는 로컬 PC에서 명령어를 입력하여 서버와 상호작용합니다. 운영체제의 구조는 사용자, Shell, Kernel, 하드웨어로 구성되며, 이들 간의 정보 처리 흐름은 명확하게 정의됩니다. WSL2와 AWS EC2 환경에서 각각의 Shell 사용 방식이 설명됩니다.
-
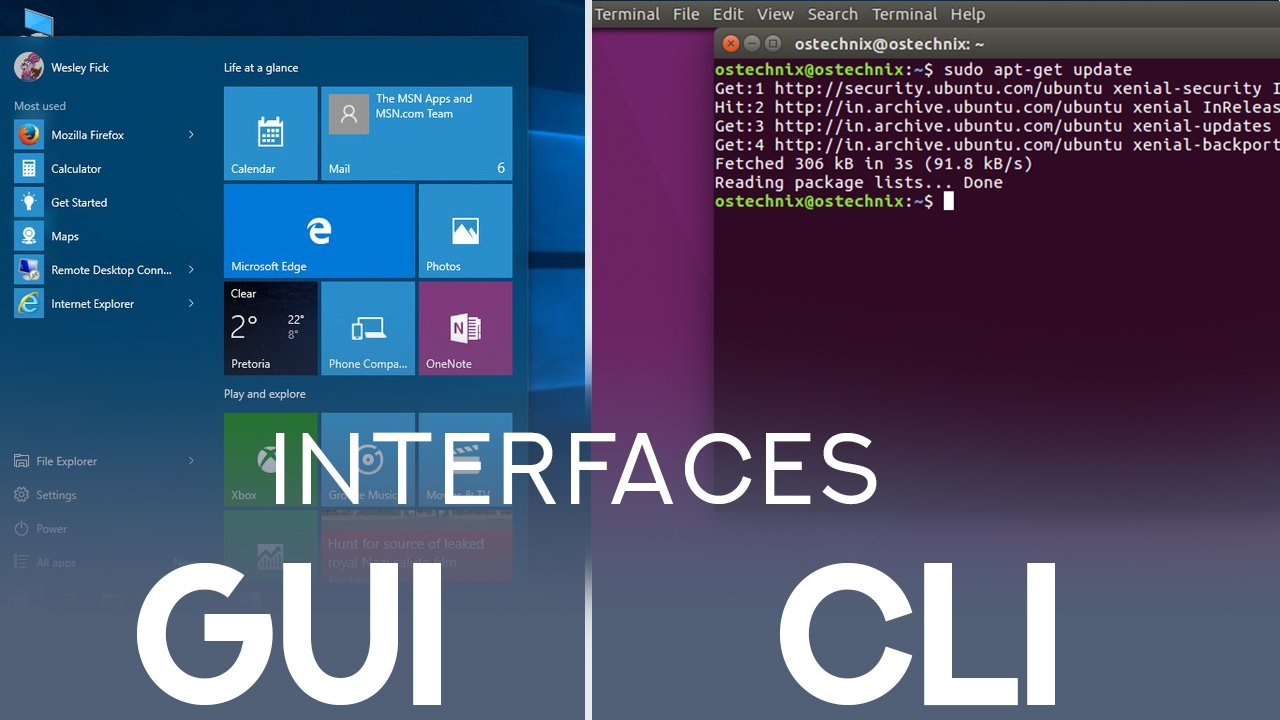 OS User Interface (CLI vs GUI)
OS User Interface (CLI vs GUI)CLI(명령줄 인터페이스)는 키보드를 통해 명령어를 입력하여 자원을 적게 사용하고 빠르게 작업할 수 있으며, 원격 서버 관리에 필수적이다. 반면, GUI(그래픽 사용자 인터페이스)는 시각적 요소를 통해 조작하며 입문자에게 친숙하지만 리눅스 서버 환경에서는 일반적으로 사용되지 않는다. CLI는 정밀 제어와 자동화에 강점을 가지며, GUI는 시각적 환경에서의 조작에 유리하다. 두 방식의 비교표에서는 서버 환경 사용 가능성, 원격 접속 지원, 사용 목적, 속도 및 자원 사용 등 다양한 항목에서 차이를 보여준다.
-
 앱 분석 - EBS의 Web App (Danchoo+)
앱 분석 - EBS의 Web App (Danchoo+)EBS의 Danchoo+는 AI 진단, 추천, 분석을 통해 학생의 학습을 지원하지만, 실제로는 규칙 기반 시스템과 간단한 통계 분석(Item2Vec)을 사용한다. 각 단계에서 진단, 추천, 분석, 결과 제공이 이루어지며, 이는 사용자 맞춤화에는 한계가 있지만 정책기관의 요구를 충족시킨다. 향후 Transformer 기반 모델과 강화학습을 통해 발전할 가능성이 있다.
- LLM Deep Research에서의 핵심요소
대규모 언어 모델(LLM)의 심층 연구는 파라미터 수 경쟁을 넘어, 하이퍼파라미터 최적화, 배치 크기, 에폭, 학습률 스케줄링 등 핵심 요소를 정밀하게 설계하고, 연산 자원의 효율적 사용을 강조합니다. 이를 통해 학습 안정성과 효율성을 동시에 확보하며, LLM의 확장성과 서비스 가치를 높이는 것이 중요합니다. 경쟁력은 규모가 아닌 정밀성과 효율성에 기반해야 합니다.
-
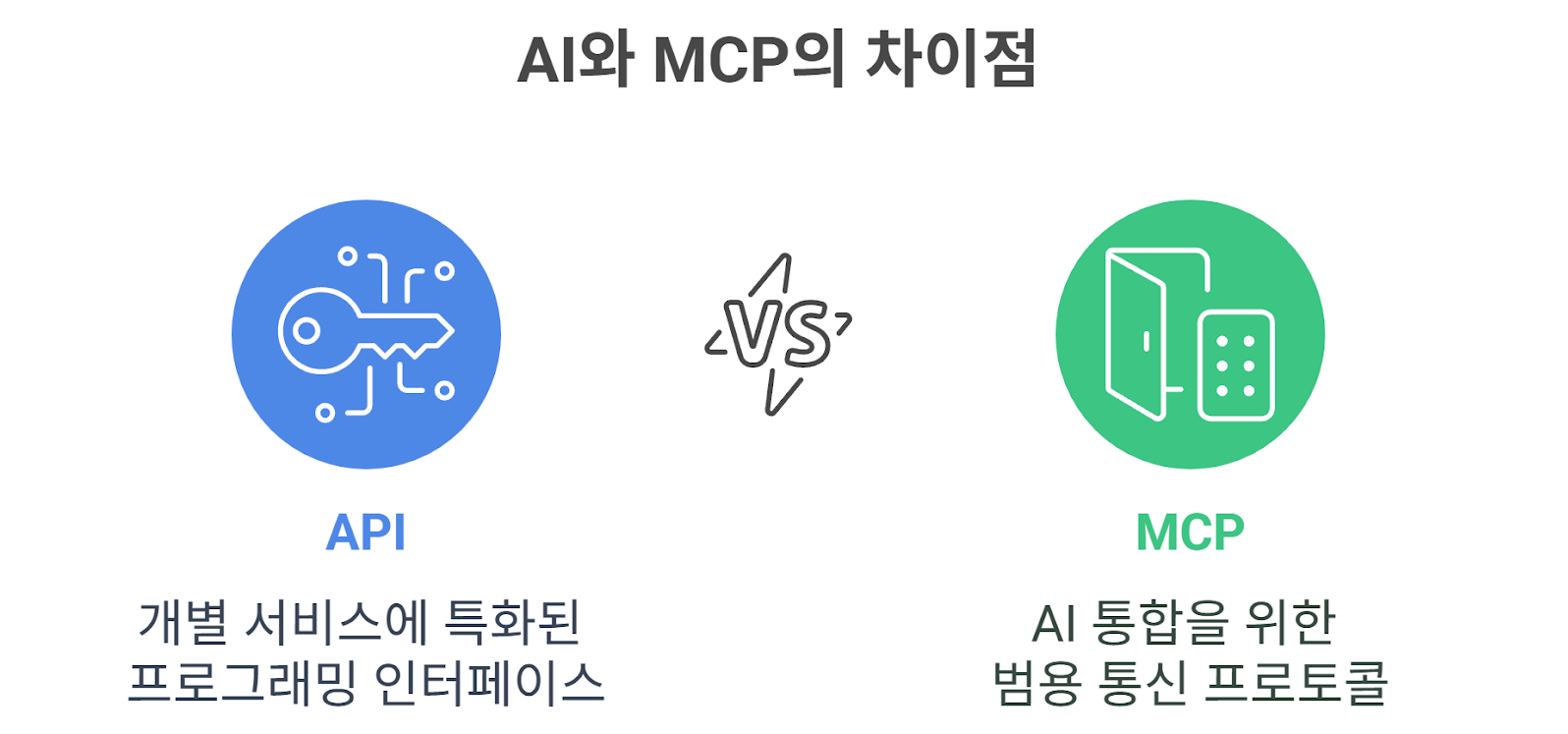 API vs MCP
API vs MCPAPI는 개발자가 요청에 따라 데이터를 가져오는 수동적 연결 방식인 반면, MCP는 LLM이 스스로 도구를 판단하여 활용하는 능동적 방식이다. 두 프로토콜은 연결의 목적은 같지만, 중심 주체와 데이터 특성에서 차이가 있다. API는 기능 호출과 단순 데이터 전송에 중점을 두고, MCP는 문맥과 대화 흐름을 통합하여 외부 도구를 활용한다.
- HW: 병렬 연산 계층 구조와 CUDA 독점의 실체 (2025)
대규모 LLM 시대의 핵심은 병렬 연산 계층 구조와 생태계 독점성에 있으며, NVIDIA의 CUDA가 사실상 유일한 상용 표준으로 자리잡았다. 대부분의 LLM은 PyTorch와 NVIDIA CUDA에 의존하고 있으며, OpenCL과 같은 대안은 실효성이 제한적이다. 병렬 연산의 성공은 하드웨어 설계, 컴파일러, SDK, 라이브러리, 프레임워크의 통합 역량에 달려 있다. OpenCL과 FPGA는 다양한 하드웨어를 지원하지만, LLM 개발에는 거의 사용되지 않는다.
-
 Database 구조 - Schema와 DB 종류
Database 구조 - Schema와 DB 종류스키마는 데이터베이스의 데이터 구조와 구성 방식을 정의하며, 데이터 무결성 유지, 타입 표준화, 관계 정의 등의 기능을 수행한다. 데이터베이스 유형으로는 관계형, 문서형, 키-값, 벡터 DB가 있으며, 각 유형은 스키마 특성과 저장 방식이 다르다. 문서형 DB는 JSON/BSON 형식으로 데이터를 저장하며 유연한 구조를 제공하고, 키-값 DB는 단순한 Key-Value 쌍으로 빠른 조회 성능을 자랑한다. 벡터 DB는 임베딩 벡터 기반의 유사도 검색을 지원한다.
-
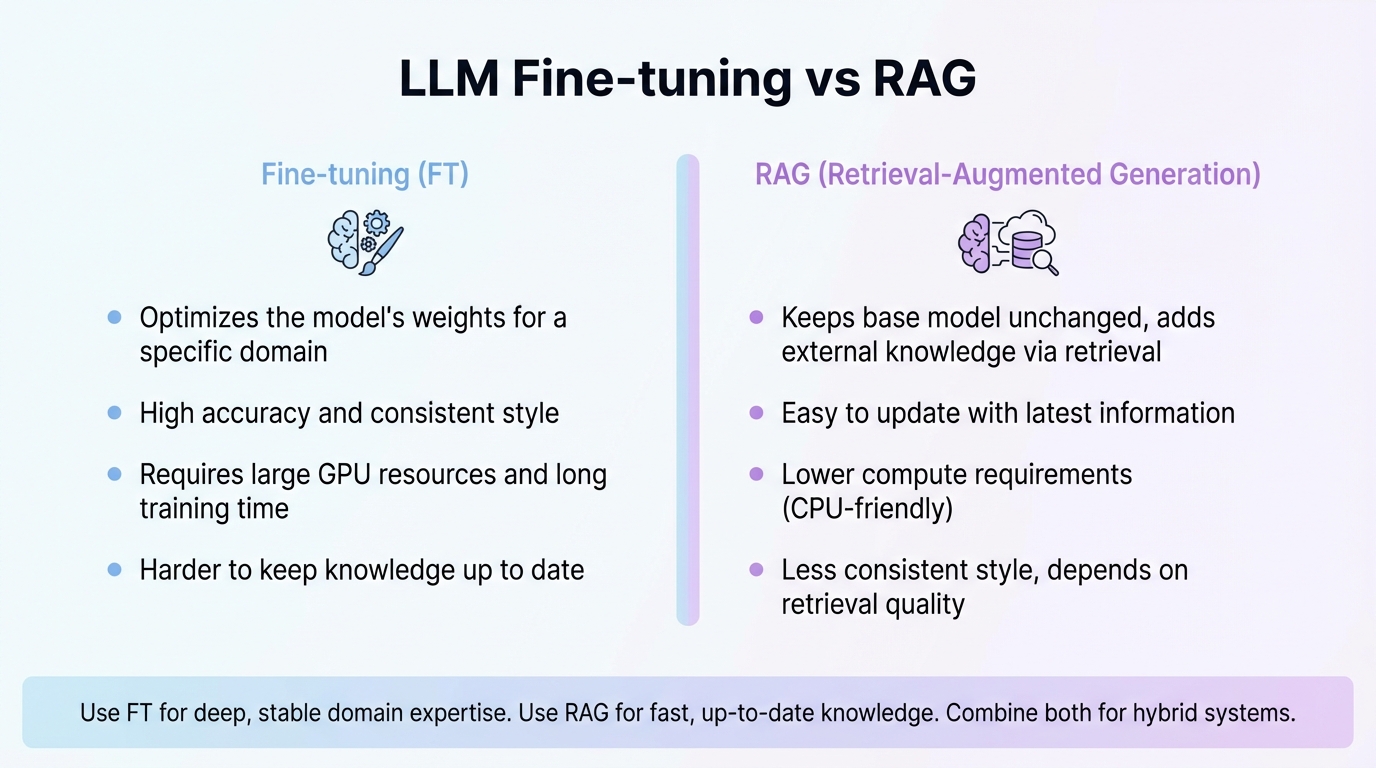 LLM Fine-tuning vs RAG
LLM Fine-tuning vs RAG대규모 언어 모델(LLM)의 미세조정(Fine-tuning)과 검색 증강 생성(RAG) 방식은 각각의 장단점이 있다. 미세조정은 특정 데이터에 대한 높은 정확도와 일관된 문체를 제공하지만, 높은 연산 자원과 긴 학습 시간을 요구한다. 반면, RAG는 외부 데이터베이스에서 정보를 실시간으로 검색하여 빠른 구현과 최신 정보 반영이 용이하며 낮은 연산 자원으로 운영 가능하다. 프로젝트의 요구 사항에 따라 적절한 방식을 선택해야 하며, 두 방식을 혼합하여 사용하는 하이브리드 모델도 효과적이다.
-
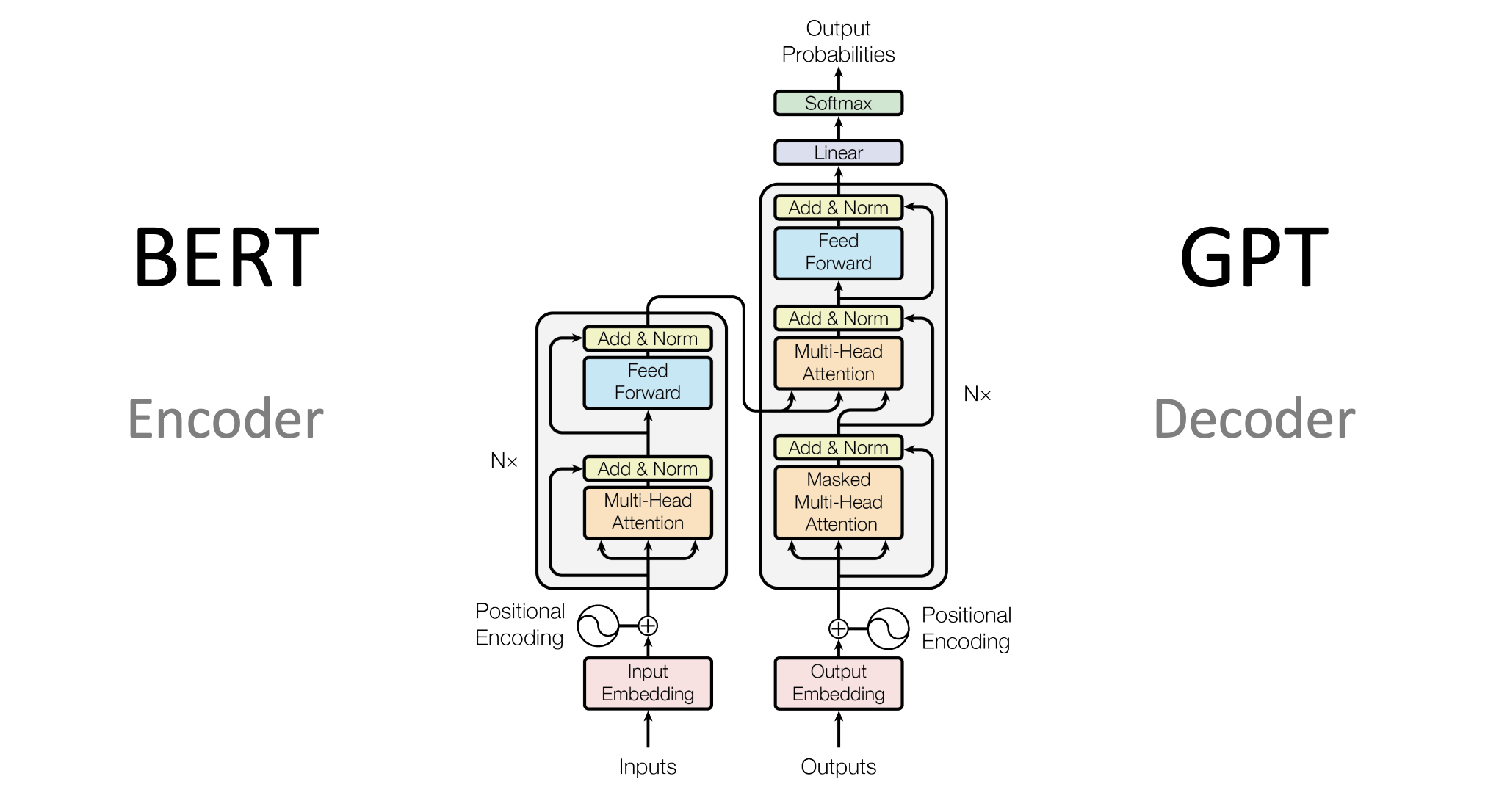 LLM 차이점을 만드는 핵심요소
LLM 차이점을 만드는 핵심요소최신 대규모 언어 모델(LLM)의 성능은 입력 데이터의 품질, Transformer 아키텍처의 유형, 학습 방식, 추론 최적화 기법에 따라 달라진다. LLM은 문장 생성, 번역, 요약 등 다양한 자연어 처리 태스크를 수행하며, 입력 데이터의 토큰화 방식, Fine-tuning 전략, 강화 학습 적용 여부가 중요한 요소로 작용한다. 각 모델은 이러한 요소들의 조합에 따라 고유한 강점과 사용 시나리오를 가지게 된다.
- LLM Fine-tuning (LoRA 방식) 실습
대규모 언어 모델(LLM)을 LoRA 방식으로 미세 조정하는 방법을 안내하며, 사전 학습 모델과 토크나이저 불러오기, 학습 데이터셋 준비, 모델 경량화, Trainer 설정 및 Fine-tuning 실행, 모델 저장, Ollama 실행용 모델 변환, 로컬 실행 예시를 포함합니다. 이를 통해 다양한 오픈소스 LLM을 효율적으로 배포할 수 있습니다.
-
 Web App Full Stack 개발 기초
Web App Full Stack 개발 기초프론트엔드는 사용자 인터페이스(UI)를 구축하며, HTML, CSS, JavaScript가 주요 언어로 사용된다. 백엔드는 데이터 처리와 서버 로직을 담당하며, Node.js, Python, Java, PHP, C# 등의 언어가 사용된다. API를 통해 프론트엔드와 백엔드 간의 데이터 통신이 이루어지며, RESTful API와 GraphQL이 주요 기술이다. 각 언어별로 다양한 프레임워크가 존재하여 개발 생산성을 높인다.