확률변수(random variable)는 숫자가 아닌 함수이기 때문에 직관적으로 이해하기 어렵지만, 모든 특성은 '확률 분포(probability distribution)'라는 함수로 설명할 수 있다. 확률 분포의 주요 특성을 나타내는 숫자 중 쉽게 계산할 수 있는 대표적인 두 가지는 '평균'값과 '분산값'이다. 일반적인 확률분포에서는 이 두 숫자만 정확히 계산하면 충분한 정보를 얻을 수 있다. 평균값은 분포의 1차 모멘트, 표준편차의 제곱인 분산값은 2차 모멘트라고 부른다. 추가로 3차 모멘트는 왜도(skewness), 4차 모멘트는 첨도(kurtosis)라고 한다.
한편, 대수학, 기하학, 미적분학 등에는 각 분야에서 가장 중요하게 여겨지는 "fundamental theorem"이 있다. 소인수분해정리, 일반적 부피형식, 일반화된 스톡스 정리 등이 그 예이다. 확률론에서 가장 중요한 정리는 무엇일까? 바로 중심극한정리(Central Limit theorem)이다. 이 정리는 모집단에서 충분히 많이 잘 뽑힌 표본들로 구성된 '표본평균'이라는 새로운 확률변수의 특성을 설명한다. 주의할 점은 표본집단의 평균값이 모집단의 평균값과 동일하지 않다는 것이다. 대수의 법칙(law of large numbers)은 표본 수가 충분히 많으면 표본평균으로 모집단의 평균값을 근사할 수 있다고 말한다(point estimate). 반면 중심극한정리는 표본평균이라는 확률변수의 분포가 모집단의 평균값을 중심으로 좌우대칭인 '정규분포'를 따른다고 설명한다.
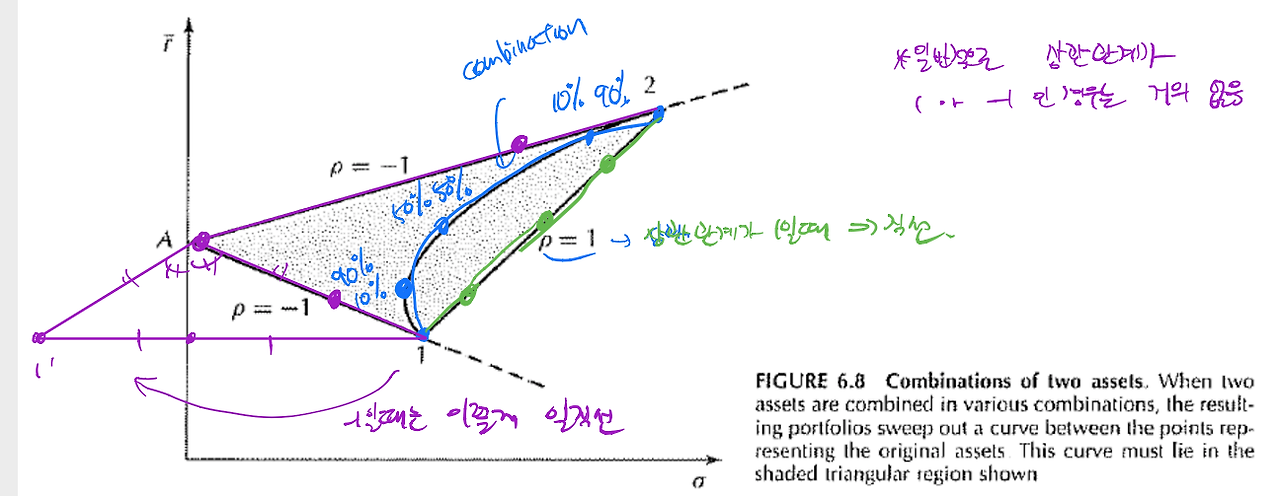
확률분포 중에 매우 특이한 정규분포 (Normal distribution)는 평균값과 표준편차라는 두 가지 값만으로 완전히 기술할 수 있다. 따라서 여러 확률변수의 분포가 모두 정규분포를 따를 경우, '표준편차-평균 좌표체계(volatility-mean coordinate system)'가 매우 유용하다. 반면 결합 확률분포가 결합 정규분포가 아닌 경우에는 이 좌표체계의 유용성은 매우 제한될 수 있다.
- x축 = 표준편차 Standard Deviation = 표준 변동성 volatility = 2nd moment of distribution
- y축 = 평균 mean, average, math expectation = 1st moment of distribution
금융론에는 1950년대에 개발된 평균-분산 이론(Mean-Variance theory)이 있다. 이는 표준편차-평균 좌표체계를 활용한 이론이다. 예를 들어, MV 이론이 분석하는 것은 지난 5년 동안의 월간 주가상승률의 평균값이다. 모집단 확률변수를 월간 주가상승률 이라고 할 때, 모집단의 분포를 아는 것이 이상적이지만, 과거 데이터 분석은 실용성이 제한적이고 미래 예측은 거의 불가능하기 때문에 다른 접근법을 취한다. 따라서 일반적으로 표본집단 확률변수인 표본평균 을 분석하고 모형화한다. 중심극한정리에 따르면 MV 이론에서 설명하는 의 분포는 거의 정규분포 형태를 띤다. 이로써 표준편차-평균 좌표체계를 활용할 수 있는 최소한의 조건이 충족된다.
- x 축 = where if each sample is IID.
- y 축 = if each sample is IID and is large.
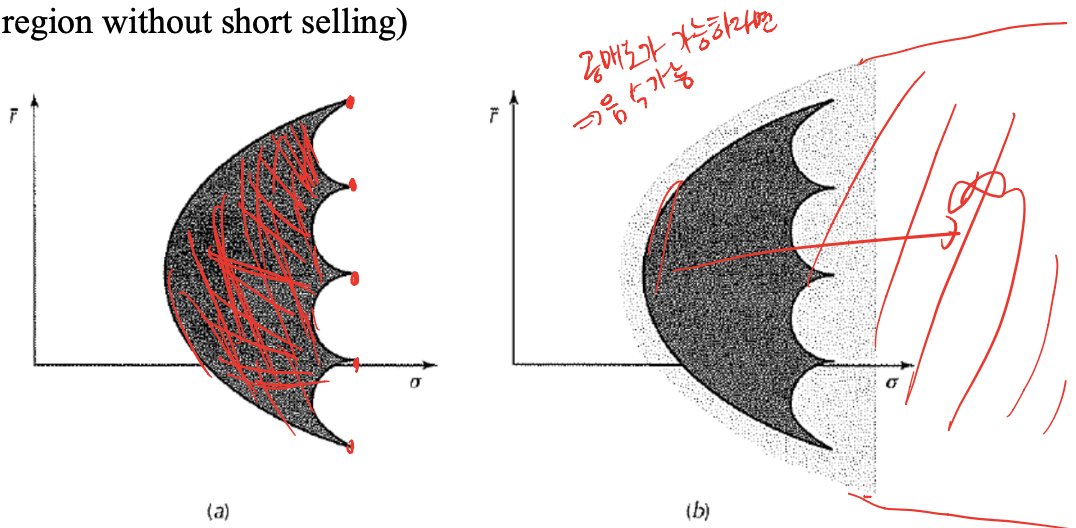
https://bookdown.org/compfinezbook/introFinRbook/Portfolio-Theory-No-Shorts.html