개념·용어
-
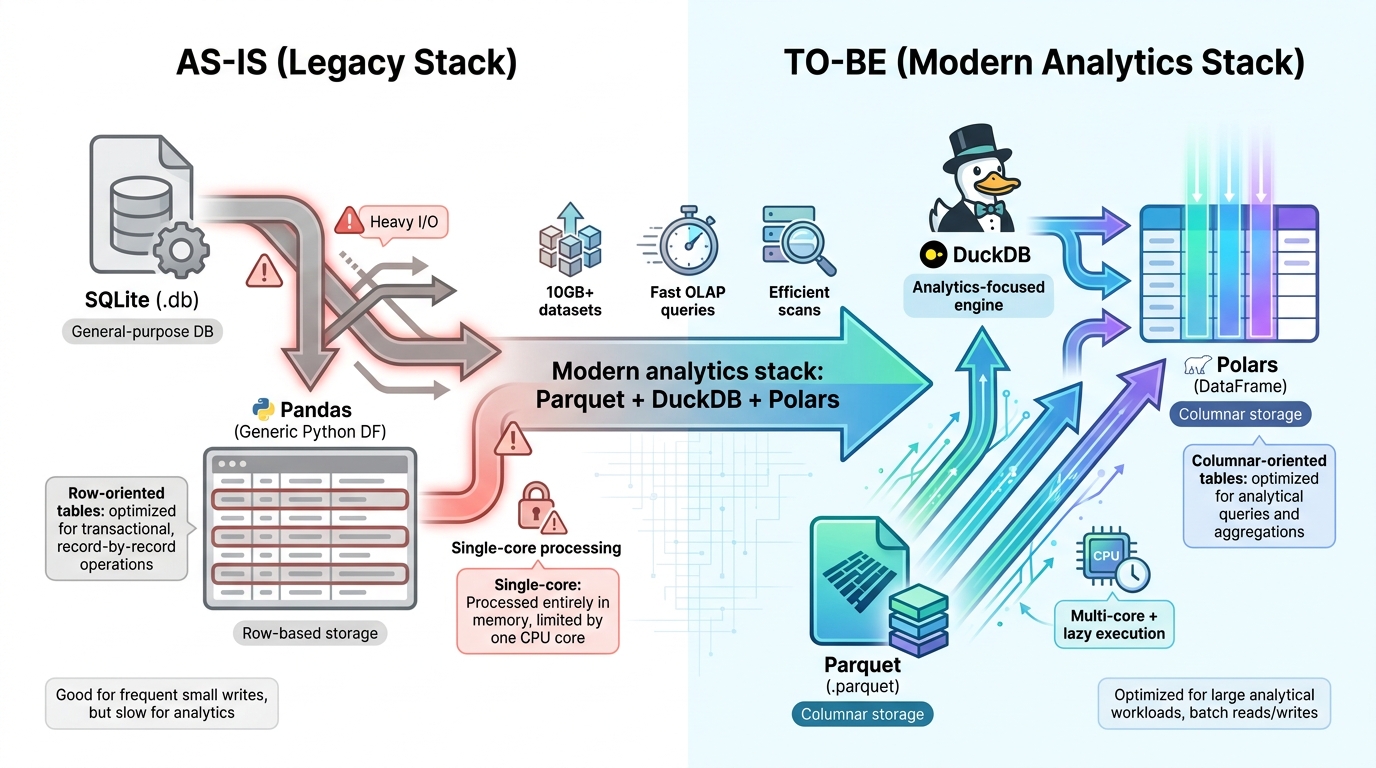 Parquet, DuckDB, Polars
Parquet, DuckDB, PolarsParquet, DuckDB, Polars 조합은 기존 SQLite와 Pandas를 대체하여 열 기반 저장, 분석 전용 인‑프로세스 DB, 멀티코어 및 Lazy 실행 데이터프레임을 제공한다. Parquet은 필요한 컬럼만 읽어 효율적인 압축을 제공하고, DuckDB는 SQL로 다양한 파일과 데이터프레임을 빠르게 집계하며, Polars는 Rust 기반으로 멀티코어와 Lazy 실행을 통해 메모리 사용을 최적화한다. 이 전환은 대용량 데이터 처리와 분석 속도 향상을 목표로 하지만, 빈번한 트랜잭션, Polars 학습 비용, 일부 라이브러리 호환성 등 제한 사항도 존재한다.
-
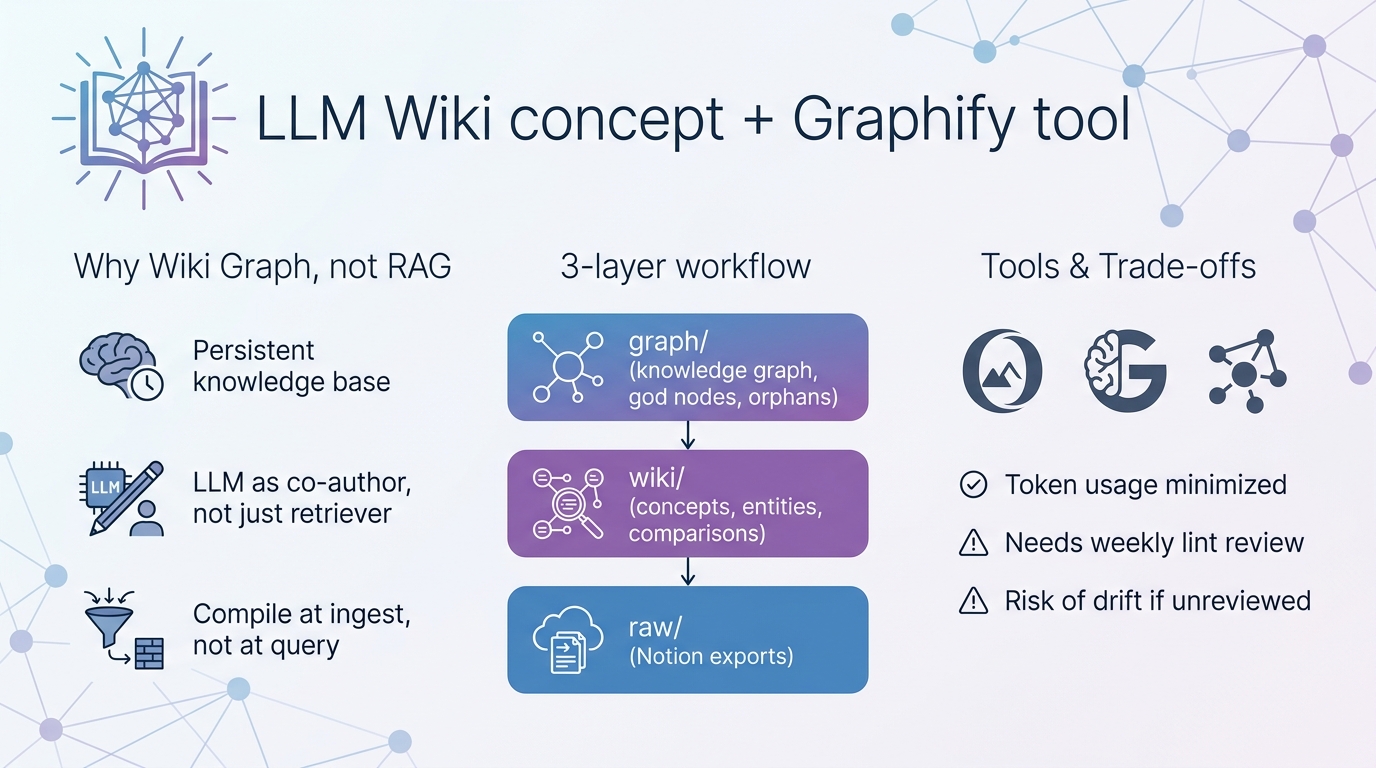 LLM Wiki concept + Graphify tool
LLM Wiki concept + Graphify toolLLM Wiki와 Graphify를 활용해 Notion에서 내보낸 원고를 wiki 형태로 전환하고, 의미론적 지식 그래프를 자동 생성·관리하여 토큰 사용을 최소화하면서 경제학 책의 목차와 내용을 지속적으로 업데이트하고 검증하는 워크플로우를 구축한다.
-
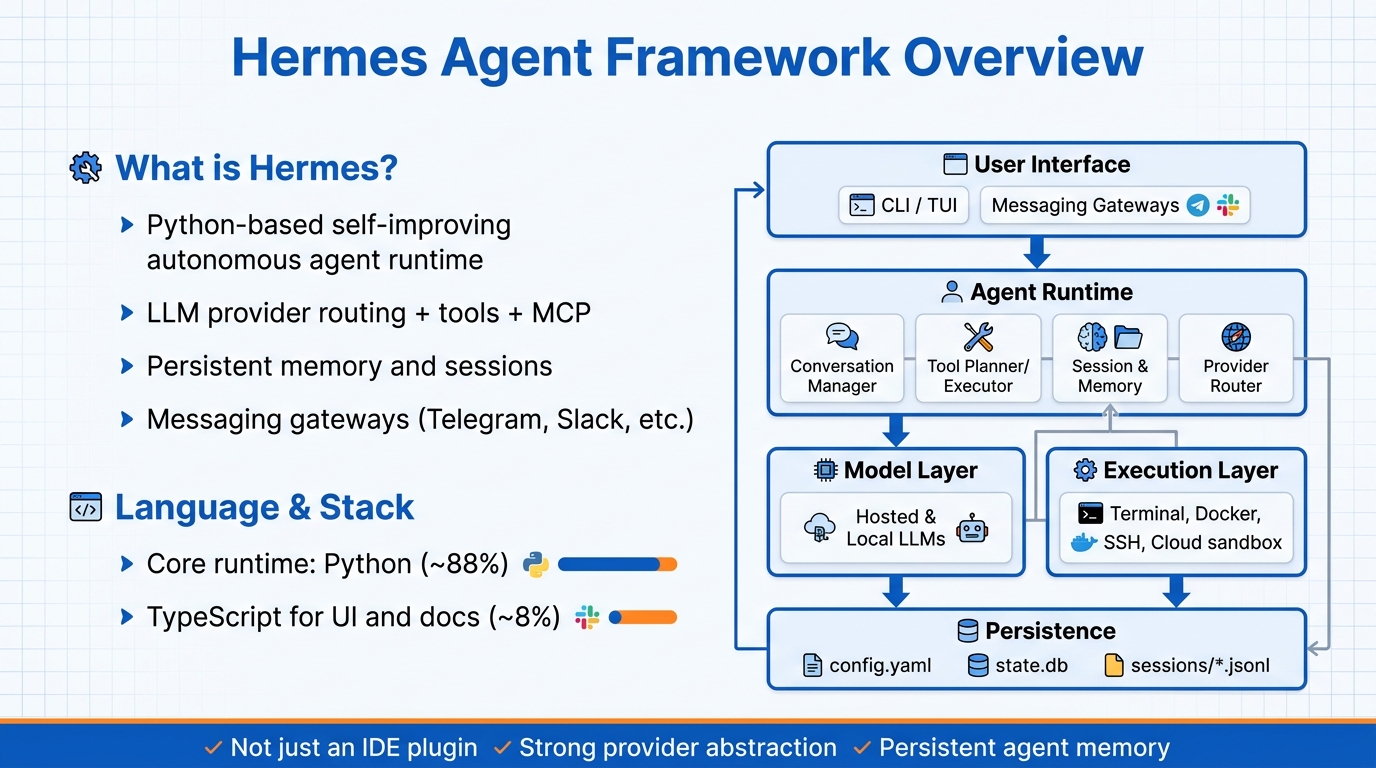 Hermes Agent Framework 개요
Hermes Agent Framework 개요Hermes Agent는 Python 기반의 self‑improving autonomous agent 프레임워크로, LLM 제공자 라우팅, 영구 메모리/세션, 스킬, MCP/툴, 메시징 게이트웨이, 샌드박스 실행을 결합한다. 핵심 런타임은 Python이며 CLI/TUI와 다양한 메시징 채널을 통해 작동하고, SQLite와 JSONL을 이용한 지속적인 세션·메모리를 제공한다. LLM 제공자는 클라우드와 로컬 모델을 모두 지원하고, 도구 실행은 로컬 터미널, Docker, SSH, 클라우드 샌드박스 등 다양한 백엔드에서 가능하며, 스킬·MCP·툴을 통해 확장성을 갖는다.
-
 AI 반도체 시장 비유: 낙관론 vs 비관론
AI 반도체 시장 비유: 낙관론 vs 비관론AI 반도체와 데이터센터를 자동차에 비유해 엔진(반도체), 차체(데이터센터), 연료(전력), 도로(전송 인프라), 운임(AI 서비스 매출) 각각의 역할과 상호 의존성을 강조하고, 현재 투자 흐름이 엔진에만 집중돼 병목 현상이 발생하고 있음을 지적한다. 엔진 효율 향상과 장기 인프라 구축이 동시에 이루어져야 성장 지속이 가능하며, 도로·연료 병목, CAPEX 둔화, 매출 성장 둔화 등 다중 신호가 겹칠 경우 비관론이 현실화될 수 있다는 점을 제시한다.
-
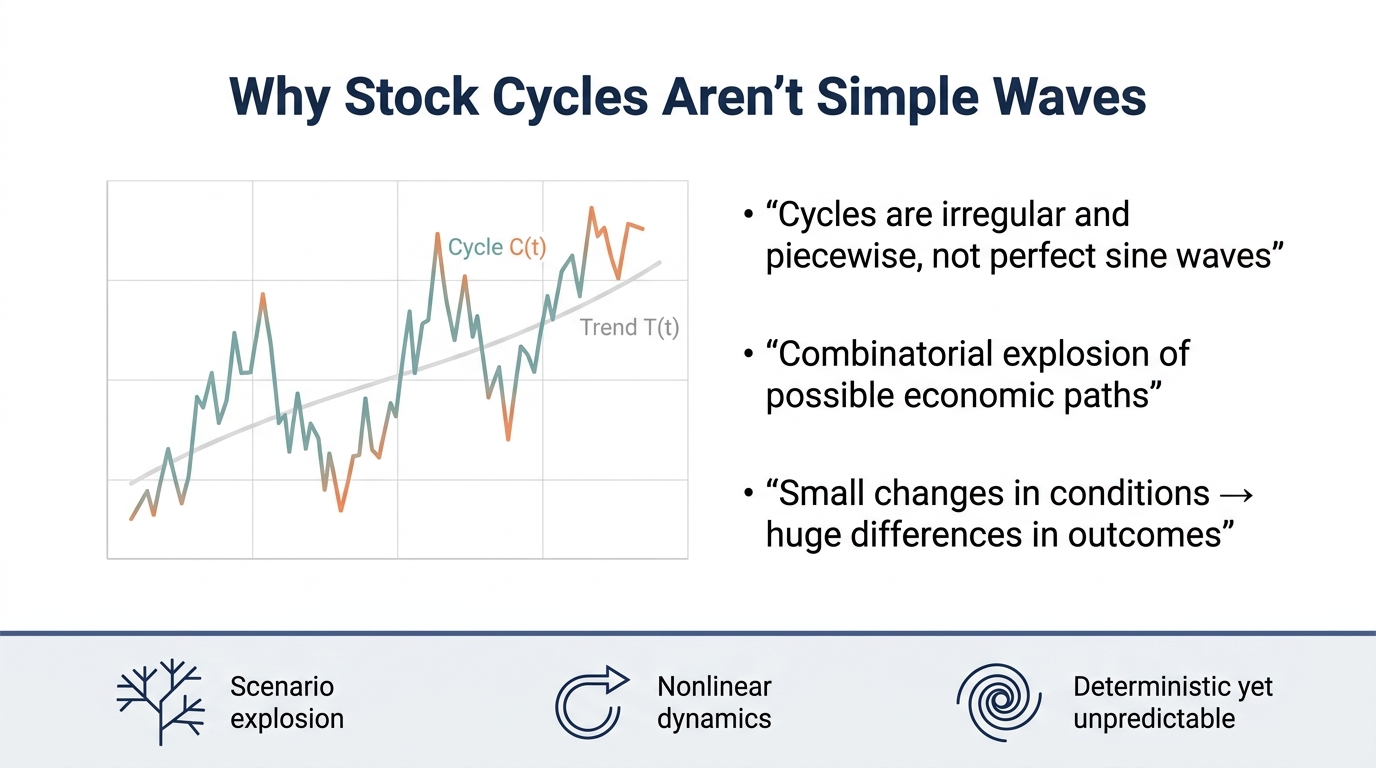 주식 시장의 변동성을 단순한 주기함수로 환원할 수 없는 이유
주식 시장의 변동성을 단순한 주기함수로 환원할 수 없는 이유주가 변동성을 단순한 주기함수로 모델링할 수 없는 이유는 경제 시스템이 비선형·비결정적이며, 단계별 기간과 곡률이 가변적인 조합론적 복잡성을 가지고 있기 때문이다. 이러한 복잡성은 상태 전이 경로의 수가 급격히 증가하고, 마르코프 성질이 적용되지 않아 예측 가능성을 크게 저해한다. 따라서 장기적 상승 추세는 관측되지만, 단기적 변동을 정확히 예측하는 것은 통계적으로 거의 불가능에 가깝다.
-
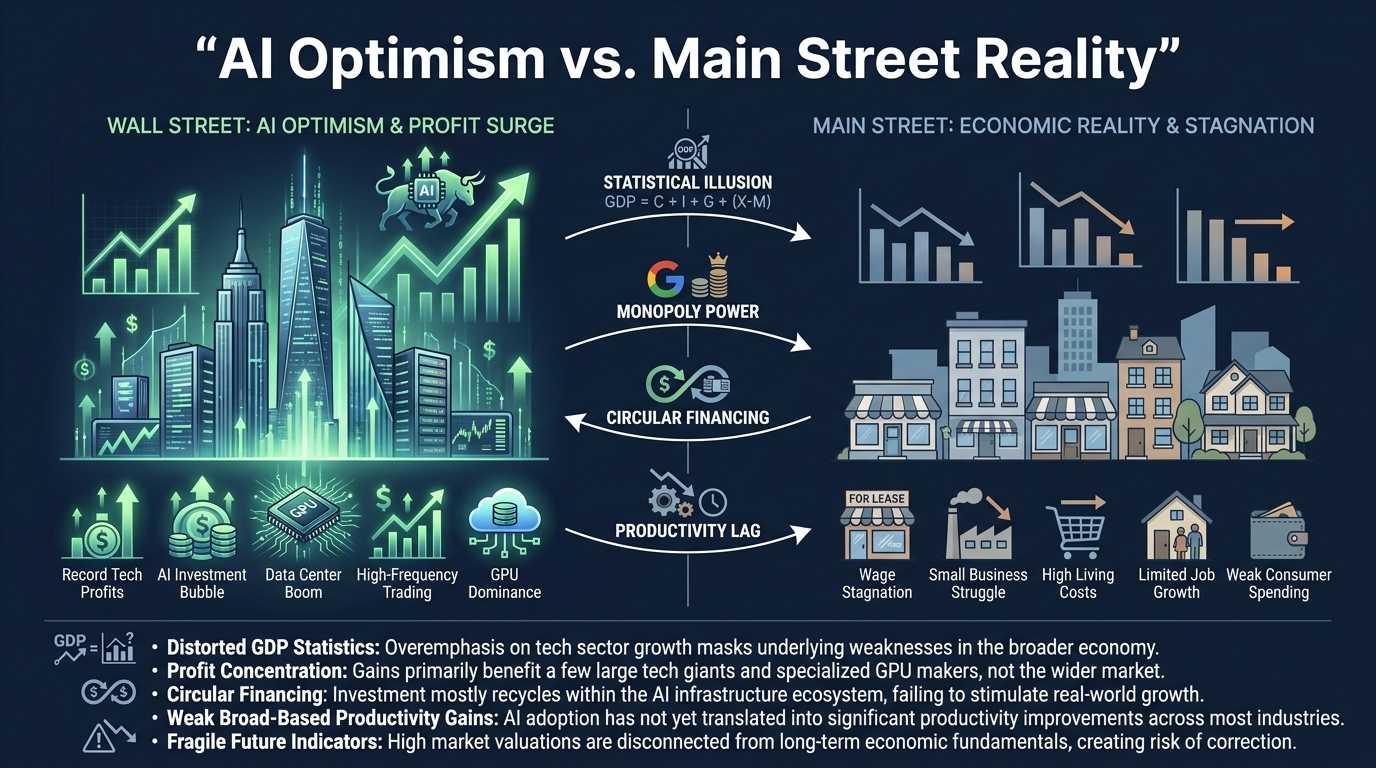 AI 낙관론 Wallstreet의 주장에 대한 AI 비관론 Mainstreet의 비판
AI 낙관론 Wallstreet의 주장에 대한 AI 비관론 Mainstreet의 비판AI 낙관론이 제시한 실물 경제 성장과 물가 둔화는 통계적 착시, 독점 구조, 순환 금융을 통한 회계적 이익 부풀리기에 기반한다. 주요 빅테크의 대규모 CapEx와 AI 인프라 내부 순환 거래가 매출 성장의 약 30%를 차지할 가능성이 있으며, 이는 NVDA와 OpenAI 등 몇몇 기업에 이익이 집중되는 구조를 만든다. 시장 성장과 생산성 향상 주장은 제한적이며, 가격 탄력성 차이와 섹터별 이익 편중이 존재한다. 향후 12~24개월 내 8가지 검증 가능한 지표를 통해 낙관론과 비관론 신호를 판단하고, 특정 매출 성장 및 ARR 정체 등 조건이 충족될 경우 AI 관련 포지션을 재평가해야 한다.
-
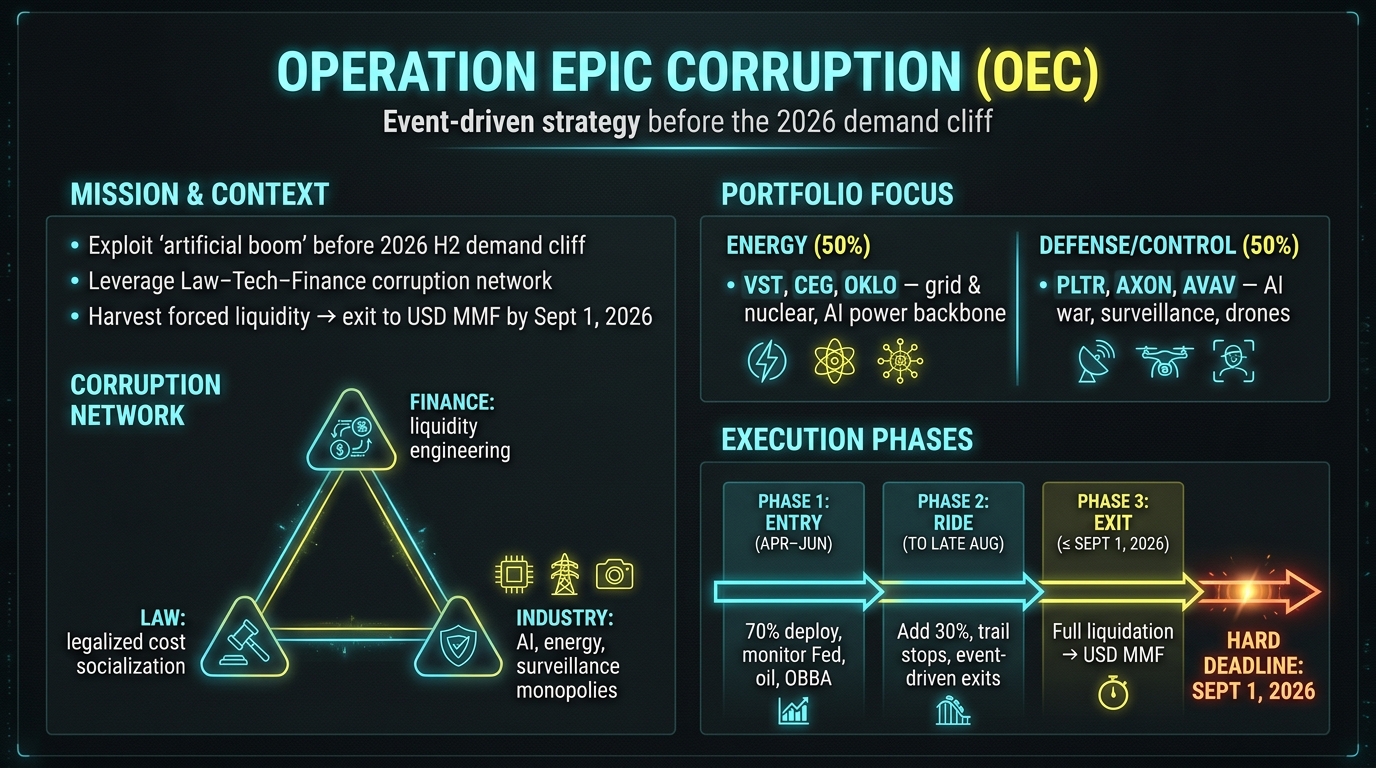 Operation Epic Corruption
Operation Epic CorruptionOperation Epic Corruption은 2026년 하반기에 예상되는 전역적 수요 절벽 전까지 트럼프 행정부와 실리콘밸리 자본이 만든 인위적 호황을 탈취하기 위한 이벤트‑드리븐 투자 전략이다. 부패한 금융·법·산업 네트워크가 강제 유동성을 공급하고 법적 루프를 통해 비용을 사회화하는 구조를 활용해, 에너지와 방산 섹터에 집중된 포트폴리오에 자본을 투입하고, 지정된 조건이 충족되면 단계별로 자산을 매도해 달러 MMF로 전환한다. 전략은 9월 1일까지 모든 포지션을 청산하도록 설계돼 있다.
-
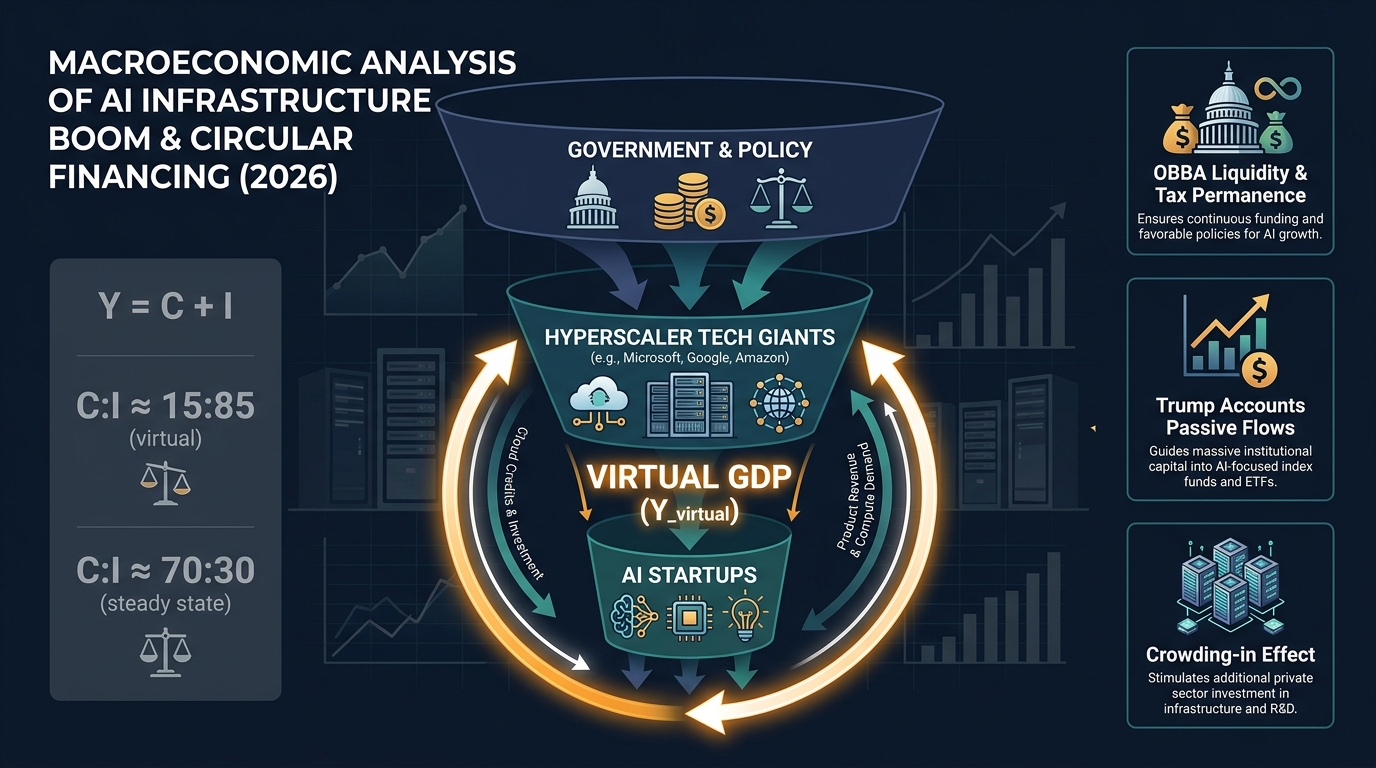 Artificial Intelligence and Artificial Boost
Artificial Intelligence and Artificial BoostAI 인프라 산업에서 하이퍼스케일러가 정부의 세제 혜택과 대규모 재정 지원을 받아 자본을 순환시켜 가상 GDP를 크게 부풀리는 메커니즘을 모델링하고, 이로 인한 투자 대비 소비 불균형과 구조적 위험을 분석한다.
- LLM App Framework: LangChain vs. LlamaIndex
LangChain은 범용 LLM 앱 및 에이전트 오케스트레이션에 강점을 가지며, 다양한 통합과 복잡한 멀티스텝 워크플로우를 지원한다. 반면 LlamaIndex는 데이터 인덱싱과 검색에 중점을 두고 있으며, 다양한 인덱스 구조와 데이터 커넥터를 제공한다. 복잡한 에이전트 오케스트레이션에는 LangChain이, 대규모 문서 및 이종 데이터 RAG에는 LlamaIndex가 추천된다. 두 라이브러리는 OpenAI 도구 호출 호환성이 뛰어나다.
-
 LLM Engine: vLLM vs. Ollama
LLM Engine: vLLM vs. OllamavLLM은 SaaS 및 고성능 프로덕션 서빙에 적합하며, Ollama는 로컬 개발과 개인 사용에 적합하다. vLLM은 높은 처리량과 낮은 지연시간을 제공하며, Ollama는 설치가 간편하고 하드웨어 유연성이 뛰어나다. 두 시스템 모두 OpenAI 호환 API를 제공하지만, vLLM은 tool calling의 정확도와 스키마 강제에서 우위를 점하고 있다. 사용 시나리오에 따라 vLLM은 다수 사용자에게 API 서빙에 적합하고, Ollama는 단일 사용자 챗봇이나 로컬 실험에 적합하다.
-
 Bias–Variance–Noise Tradeoff: 열린계에서의 MSE 분해
Bias–Variance–Noise Tradeoff: 열린계에서의 MSE 분해고전적 bias–variance–noise 분해는 닫힌계에 기반하나, 열린계에서는 구조적 이동, 상태 미명세, 시변 잡음을 포함한 확장된 MSE 분해가 필요하다. 예측 오차는 추정 오차, 구조적 이동, 상태 미명세, 잡음으로 나뉘며, 특히 구조적 이동이 OOS 오류의 주요 원인으로 작용한다. 금융 시장에서의 사례를 통해 이러한 요소들이 어떻게 상호작용하는지를 설명하며, 잡음 구조 이해와 관리가 성능 향상에 필수적임을 강조한다.
-
 정적 사이트 SEO 최적화 전략: 데이터 구조화 (Hugo 기준)
정적 사이트 SEO 최적화 전략: 데이터 구조화 (Hugo 기준)정적 사이트의 SEO 최적화를 위해 Front Matter를 구조화 데이터(JSON-LD)로 변환하는 방법을 설명합니다. 기존의 단순 메타태그에서 의미 중심의 구조화 데이터로 전환하여 검색엔진이 콘텐츠를 더 잘 이해하도록 돕습니다. 데이터 변환 프로세스는 정의, 추출, 변환, 삽입의 단계로 구성되며, 최종적으로 검색엔진 신뢰도와 클릭률(CTR) 상승 효과를 기대할 수 있습니다.
- OS: lununtu + windows os 듀얼부팅 grub 설정 기초
GRUB에서 Windows를 기본 부팅으로 설정하려면 /etc/default/grub 파일에서 GRUB_DEFAULT 값을 Windows 항목으로 지정하고, GRUB 설정을 갱신해야 한다. 또한, 부팅 시 3초 동안 GRUB 메뉴를 표시하고 선택이 없으면 자동으로 Windows가 부팅되도록 설정할 수 있다.
- Efficient Portfolio Strategy: A TBTF Approach to Stock Market Investment
자본주의 사회에서 자산 격차가 커지는 현상을 분석하고, 'Too Big to Fail' 전략을 통해 안정적인 주식 포트폴리오를 구성하는 방법을 제시한다. 상위 1%가 주식의 대부분을 소유하고 있는 현실을 바탕으로, 대형 주식의 초과 수익률이 시장 평균보다 우수하다는 점을 강조하며, 시장 비효율성을 고려한 포트폴리오 운용 전략을 통해 투자 효율성을 높일 수 있음을 설명한다. TBTF 포트폴리오는 평균 수익률을 유지하면서도 변동성을 줄이고, 거래 비용을 최소화하는 장점을 가진다.
-
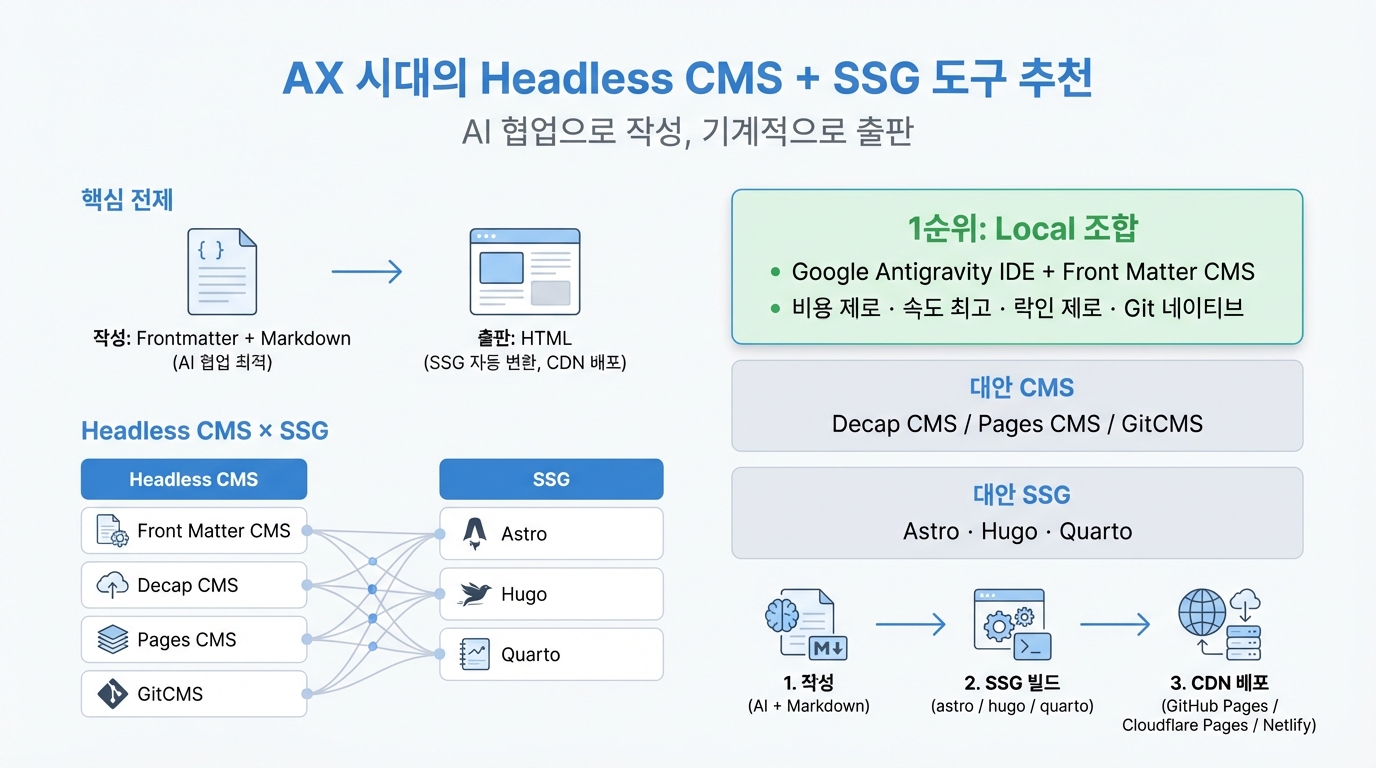 AX 시대의 Headless CMS + SSG 도구 추천
AX 시대의 Headless CMS + SSG 도구 추천AX 시대에 최적화된 Headless CMS와 SSG 조합을 추천하며, AI와 협업하여 콘텐츠를 작성하고 기계적으로 출판하는 워크플로우를 설명한다. Frontmatter와 Markdown을 사용하여 AI가 메타데이터를 쉽게 처리할 수 있도록 하고, 다양한 CMS와 SSG의 조합을 통해 유연한 선택이 가능하다. 추천 CMS로는 Google Antigravity IDE와 Front Matter CMS가 있으며, SSG로는 Astro, Hugo, Quarto가 있다. 빌드와 배포는 AI가 자동으로 처리하여 효율성을 높인다.
-
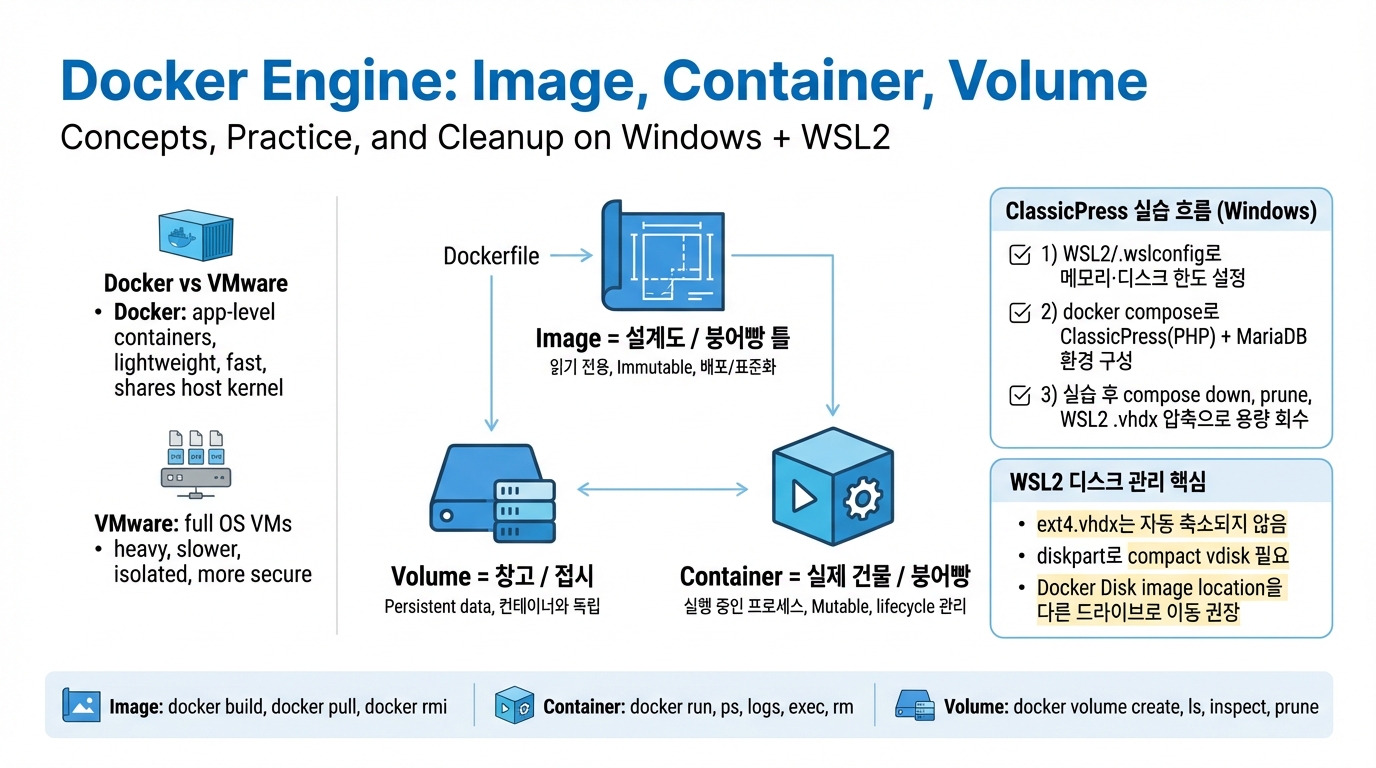 Docker Engine 실습으로 배우는 가상화 개념
Docker Engine 실습으로 배우는 가상화 개념도커 엔진은 애플리케이션을 경량화하여 실행하는 컨테이너 기반 기술로, VMware와 비교할 때 가벼우며 빠른 부팅 속도를 제공합니다. 도커는 이미지, 컨테이너, 볼륨의 세 가지 요소로 구성되며, 이미지는 실행 파일의 설계도, 컨테이너는 실행 중인 프로세스, 볼륨은 데이터를 영구적으로 저장하는 외부 저장 공간입니다. 각 요소의 주요 CLI 명령어와 함께 ClassicPress 실습 환경 구축 및 삭제 과정도 설명됩니다.
-
 LLM CLI vs OpenClaw in Mini PC
LLM CLI vs OpenClaw in Mini PCOpenClaw는 편리함을 제공하지만 보안 위험과 제어권 상실 문제로 인해 사용에 주저해야 한다. 대신 Local LLM CLI를 통해 인간이 주도하는 안전한 환경에서 코드를 검토하고 실행하는 것이 바람직하다. OpenClaw는 흥미로운 도구일 수 있지만, 소중한 프로젝트를 맡기기에는 보안과 주도권 측면에서 많은 문제가 있다.
-
 Notion AI 활용 가이드
Notion AI 활용 가이드Notion AI의 효과적인 활용법으로는 긴 문서의 특정 패턴을 추출하는 RAG 활용, 실행 가능한 항목 및 기술 용어를 추출하는 Custom AI Autofill 기능, 외부 모델을 사용하는 인터페이스의 안정성 강조가 있다. Notion과 Google 생태계의 차이점은 데이터 수집 방식, 처리 방법, 저장 방식에서 나타나며, Notion AI의 커스텀 명령어와 JAMstack 테스트 사례도 소개된다.
-
 Notion Mail · Notion Calendar의 작동원리와 “정석” 사용법
Notion Mail · Notion Calendar의 작동원리와 “정석” 사용법Notion Mail과 Notion Calendar는 이메일과 일정을 업무 운영체제로 재구성하는 도구로, Notion Mail은 Gmail과 동기화하여 인박스를 프로젝트 중심으로 관리하고, Notion Calendar는 외부 캘린더와 통합하여 시간 계획을 Notion 데이터베이스와 연결합니다. 이 두 도구는 커뮤니케이션과 시간 관리를 효율적으로 처리하기 위해 AI를 활용하며, 사용자는 메일을 처리하는 큐로, 일정을 실행 도구로 변환하여 업무 흐름을 최적화할 수 있습니다.
-
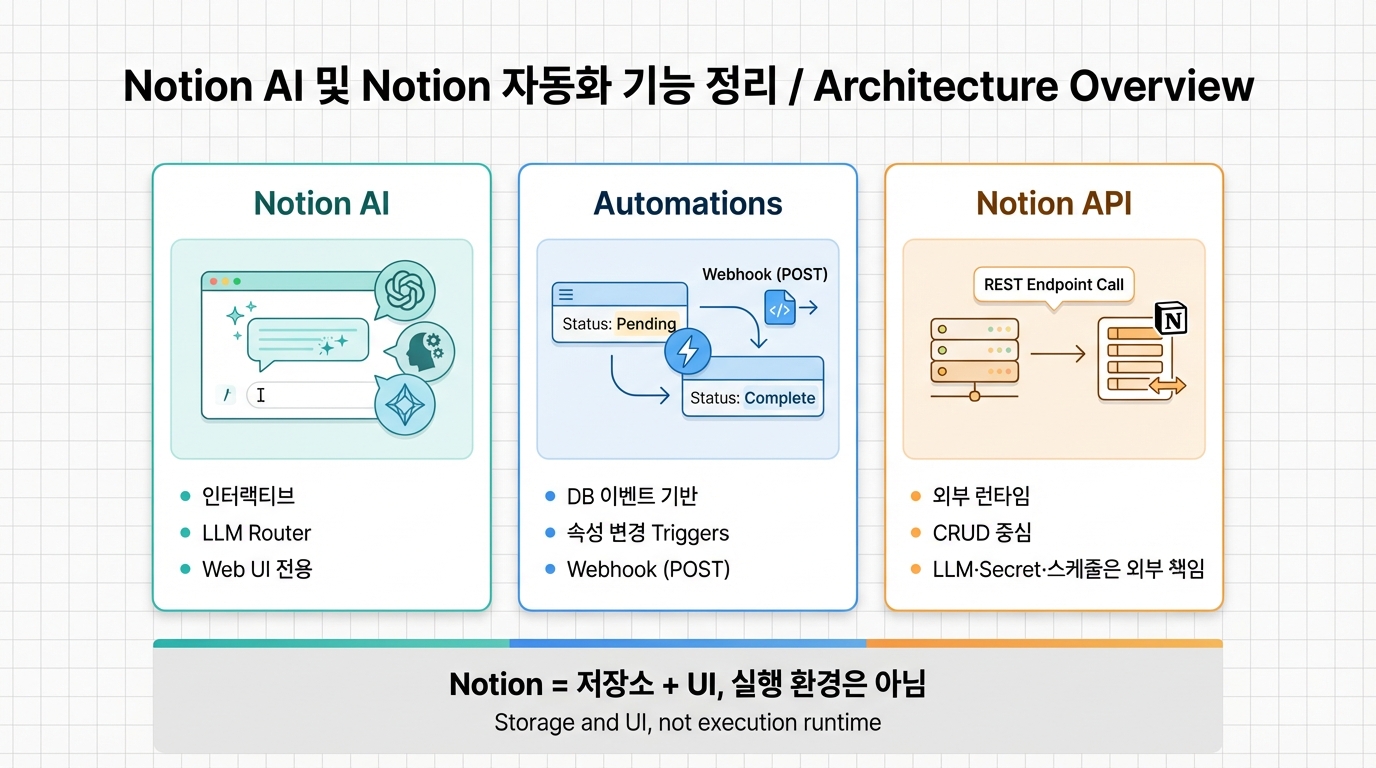 Notion AI 및 Notion 자동화 기능 정리
Notion AI 및 Notion 자동화 기능 정리Notion AI · 내부 자동화 · Notion API의 구조·능력·한계를 3축으로 비교하고, 비즈니스 시나리오별 적합 기술을 매핑한다.