모든 최신 대규모 언어 모델(LLM, Large Language Model)은 Transformer (트랜스포머) 구조를 기반으로 하지만, 입력 데이터의 품질과 양, Self-Attention (자기 주의 메커니즘) 기반 아키텍처의 유형, 다양한 Fine-tuning (미세 조정)·강화학습(Reinforcement Learning)·검색 증강 생성(RAG) 기법, 그리고 FlashAttention, KV Cache 와 같은 추론 최적화 기술에 따라 성능과 특성이 달라집니다. 본 글은 LLM 입문자가 꼭 알아야 할 4 가지 핵심 기준을 체계적으로 정리하고 주요 모델들의 특징을 통합적으로 제시하여, LLM 간의 차이점을 쉽게 이해할 수 있도록 돕습니다.
LLM의 복잡성 이해를 위한 핵심 관점
LLM (Large Language Model)은 문장 생성, 번역, 요약 등 다양한 자연어 처리(NLP, Natural Language Processing) 태스크를 수행할 수 있는 강력한 Machine Learning (ML) 모델입니다. 하지만 GPT (Generative Pre-trained Transformer) 계열만 해도 모델마다 특성이 다르고, Gemini (구글), Claude (Anthropic) 등 수많은 이름이 혼재되어 입문자에게 혼란을 줍니다. 그 차이를 만드는 가장 핵심 요소는 크게 ① 입력 데이터, ② Transformer 아키텍처, ③ 학습 방식, ④ 추론 최적화 기법 네 가지로 정리할 수 있습니다.
LLM을 구별하는 네 가지 핵심 기준
1. 입력 데이터 (Input Data): LLM 지식의 원천
LLM의 성능은 모델이 학습한 데이터의 질과 양에 의해 결정됩니다. 모델은 웹 페이지, 책, 논문, 코드 등 방대한 원본 데이터를 수집한 후, 이를 모델이 이해할 수 있는 최소 단위인 Token (토큰)으로 변환합니다. 이 토큰화 과정에서 사용되는 인코딩 방식에 따라 모델의 어휘 구성과 처리 방식이 달라집니다.
- BPE (Byte Pair Encoding): GPT (Generative Pre-trained Transformer) 계열 모델에서 주로 사용되며, 빈번하게 나타나는 문자 쌍을 하나의 새로운 토큰으로 병합하여 어휘를 구축합니다.
- SentencePiece (센텐스피스): LLaMA (라마) 계열 모델에서 주로 사용되며, 비단어 토큰(예: 공백)을 포함한 모든 입력 시퀀스를 토큰화하여 유니코드(Unicode) 문자열을 일관성 있게 처리할 수 있습니다.
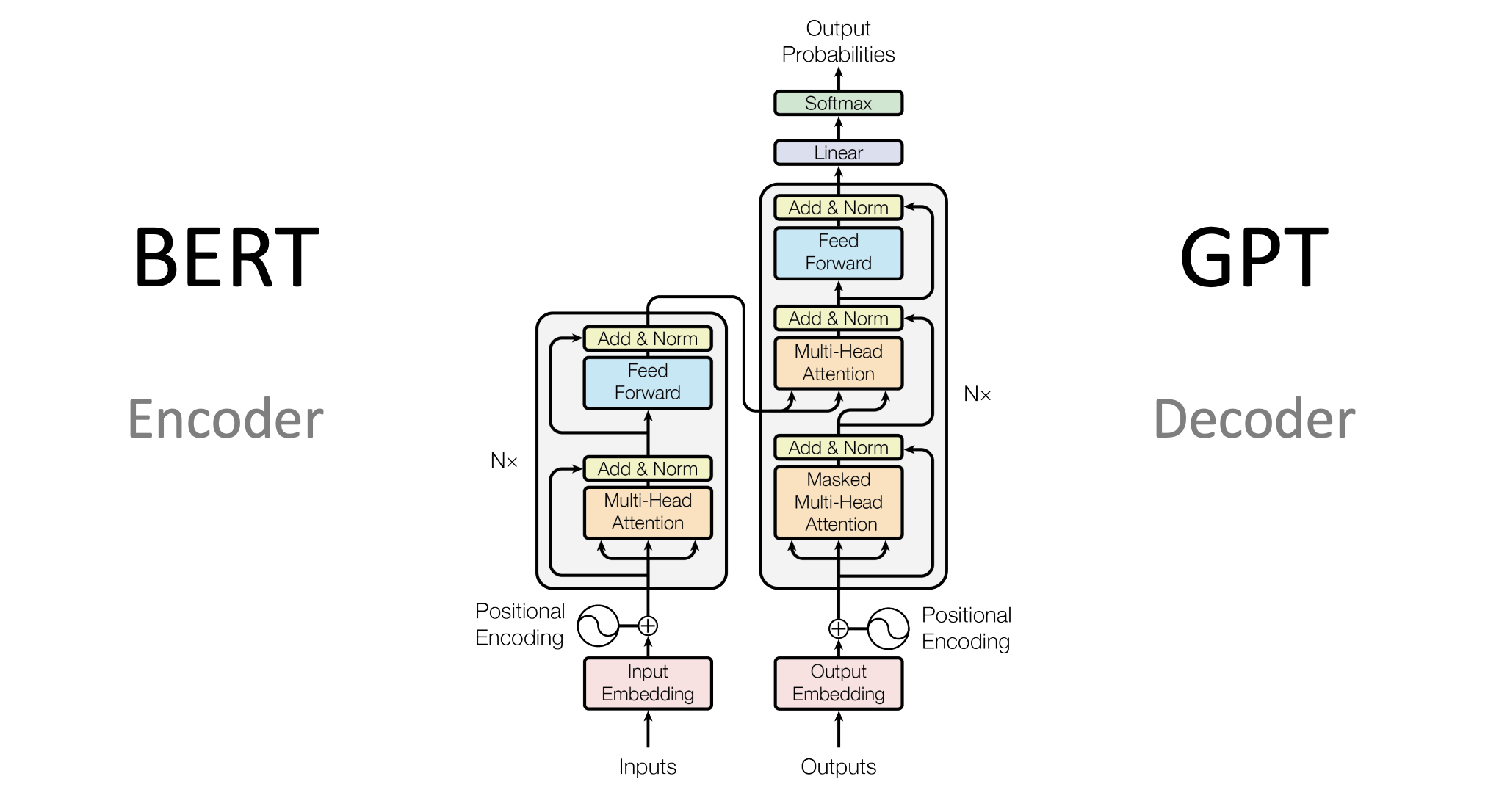
2. Transformer Architecture (트랜스포머 아키텍처): LLM의 뇌 구조
모든 최신 LLM은 2017년 Google (구글)에서 발표한 Transformer (트랜스포머) 구조를 기반으로 합니다. Transformer는 Self-Attention (자기 주의 메커니즘)을 통해 입력 시퀀스 내의 단어 간 관계를 동적으로 학습하여 문맥을 이해합니다.
- Self-Attention: 문장 내의 각 단어가 다른 모든 단어와 얼마나 관련이 있는지를 학습하여, 문맥에 따라 단어의 의미를 파악합니다.
- Multi-Head Attention (멀티 헤드 어텐션): 여러 개의 Self-Attention 메커니즘을 병렬로 사용하여 다양한 관점에서 문맥을 학습하고, 단어의 다중 의미나 복합적인 관계를 처리합니다.
- Positional Encoding (위치 인코딩): Transformer는 순환 신경망(RNN, Recurrent Neural Network)과 달리 시퀀스의 순서를 직접적으로 처리하지 못하므로, 입력 단어의 상대적/절대적 위치 정보를 추가하여 단어의 순서를 인식할 수 있도록 합니다.
Transformer 아키텍처는 크게 두 가지 주요 유형으로 나뉩니다.
| 구분 | 대표 모델 (2025년 기준) | 설명 |
| Decoder-only | GPT-4o (지피티-포오), LLaMA 3 (라마 3), Mistral 계열, Claude 3 (클로드 3) | 과거 입력만을 기반으로 다음 단어를 예측하는 Auto-Regressive (자기 회귀) 방식으로 작동합니다. 주로 텍스트 생성에 특화되어 있으며, 현재 가장 널리 사용되는 LLM 아키텍처입니다. |
| Encoder-Decoder | Gemini 1.5, T5, BART | 전체 입력을 인코더(Encoder)에서 분석하고 압축한 뒤, 디코더(Decoder)에서 이를 바탕으로 응답을 생성합니다. 번역, 요약 등 입력과 출력 간의 명확한 변환이 필요한 태스크에 적합합니다. |
3. 학습 방식 (Training Method): LLM 능력의 특화
LLM은 방대한 데이터로 일반적인 언어 능력을 습득하는 Pre-training (사전 학습) 과정을 거친 후, 특정 태스크나 목적에 맞게 능력을 최적화하는 다양한 학습 방식을 적용합니다.
| 학습 계열 | 대표 모델 (2025년 기준) | 특징 |
| Fine-tuning (미세 조정) | 사전 학습된 모델을 특정 태스크나 데이터셋에 맞게 추가 학습시키는 과정입니다. | |
| Full Fine-tuning (풀 미세 조정) | 대부분의 상용 및 오픈소스 LLM (예: LLaMA 3 기반 Fine-tuning 모델) | 모델의 모든 파라미터(Parameter)를 조정하여 세부 태스크에 가장 강력하게 최적화하는 방식입니다. 많은 컴퓨팅 자원이 필요합니다. |
| SFT (Supervised Fine-tuning) (지도 학습 미세 조정) | Alpaca (알파카), Vicuna (비쿠나) 등 Chat-tuned 모델 | 인간이 직접 레이블링(Labeling)한 정제된 데이터를 사용하여 특정 태스크에 모델을 최적화합니다. 특정 답변 스타일이나 행동을 학습시키는 데 효과적입니다. |
| LoRA (Low-Rank Adaptation) (저랭크 적응) | (대부분의 LLM에서 효율적인 Fine-tuning 기법으로 활용) | 모델의 모든 파라미터를 조정하는 대신, 일부 소수의 파라미터만 조정하여 미세 조정에 필요한 메모리와 연산량을 크게 절감합니다. |
| QLoRA (Quantized LoRA) (양자화 로라) | (대부분의 LLM에서 효율적인 Fine-tuning 기법으로 활용) | LoRA 기법에 4-bit 양자화(Quantization)를 적용하여 메모리 사용량을 더욱 극적으로 줄이면서도 성능 저하를 최소화합니다. 대규모 모델의 미세 조정을 가능하게 합니다. |
| Reinforcement Learning (RL) (강화 학습) | 모델이 환경과 상호작용하며 보상(Reward)을 최대화하도록 학습하는 방식입니다. | |
| RLHF (Reinforcement Learning with Human Feedback) (인간 피드백 기반 강화 학습) | GPT-4o (지피티-포오), Gemini 1.5 Pro (제미나이 1.5 프로), Claude 3 Opus (클로드 3 오퍼스) | 인간의 선호도 피드백을 사용하여 LLM의 응답을 최적화하는 강화 학습 기법입니다. 모델이 사용자의 의도를 더 잘 이해하고, 유해하거나 부적절한 답변을 피하도록 훈련시킵니다. |
| Pure RL (순수 강화 학습) | DeepMind (딥마인드)의 일부 연구 모델 (예: AlphaCode 2 (알파코드 2)와 같은 복합 추론 시스템) | 인간의 직접적인 피드백 없이, 환경과의 상호작용 및 보상 함수(Reward Function)를 통해 강화 학습으로 모델을 최적화합니다. 특정 복잡한 목표 달성에 유용할 수 있습니다. |
| RAG (Retrieval-Augmented Generation) (검색 증강 생성) | Command R+ (커맨드 알 플러스), GPT-4o (지피티-포오) 및 Gemini 1.5 (제미나이 1.5)의 고급 기능 | 외부 검색 시스템과 LLM을 결합하여, 실시간으로 최신 정보나 특정 데이터베이스의 정보를 검색하고 이를 바탕으로 응답을 생성합니다. 모델의 환각(Hallucination) 현상을 줄이고 정보의 정확성을 높입니다. |
| Multi-modal Learning (멀티모달 학습) | Gemini 1.5 (제미나이 1.5), GPT-4o (지피티-포오), Claude 3 Vision (클로드 3 비전) | 텍스트 외에 이미지, 오디오, 비디오 등 다양한 형태의 데이터를 함께 학습하여, 모델이 복합적인 정보를 통합적으로 이해하고 생성할 수 있도록 합니다. |
4. 추론 최적화 기법 (Inference Optimization): LLM의 실시간 활용성
학습된 LLM을 실제 서비스 환경에서 효율적으로 사용하기 위해서는 추론(Inference) 단계에서의 연산 속도와 자원 효율성을 높이는 기법이 필수적입니다. 이러한 최적화 기술은 LLM의 실시간 활용성을 결정합니다.
| 최적화 기법 | 대표 모델 (2025년 기준) | 설명 |
| FlashAttention | GPT-4o (지피티-포오), Claude 3 (클로드 3) 등 대부분의 최신 고성능 LLM | GPU (Graphics Processing Unit) 메모리 사용을 최적화하여 Attention (어텐션) 연산 속도를 크게 향상시키는 기법입니다. 긴 시퀀스(Sequence) 처리 시 효율성을 높입니다. |
| KV Cache | GPT-4o (지피티-포오), LLaMA 3 (라마 3) 등 대부분의 Auto-Regressive LLM | Transformer 디코더(Decoder)가 새로운 토큰을 생성할 때, 이전에 계산된 Key (키)와 Value (값) 행렬을 캐시(Cache)에 저장하고 재활용하여 반복적인 연산을 줄여 추론 속도를 개선합니다. |
| MoE (Mixture of Experts) | Mixtral (믹스트랄) 8x22B, GPT-4o (추정), Falcon 180B (일부 MoE 개념 활용) | 모델 내부에 여러 개의 '전문가' 네트워크를 두고, 입력 데이터에 따라 필요한 일부 전문가 모델만 활성화하여 전체 연산량을 감소시킵니다. 이는 모델의 크기는 크지만 추론 비용은 낮출 수 있는 장점이 있습니다. |
결론
대규모 언어 모델(LLM)의 성능과 특성을 가르는 핵심은 단순히 외형적인 규모(매개변수의 개수)가 아니라, 입력 데이터의 품질과 토큰화 방식, Transformer (트랜스포머) 아키텍처의 유형(Decoder-only 또는 Encoder-Decoder), Fine-tuning (미세 조정) 전략 및 RLHF (Reinforcement Learning with Human Feedback)와 같은 강화 학습 적용 여부, RAG (Retrieval-Augmented Generation) 결합 여부, 그리고 FlashAttention (플래시 어텐션), KV Cache (케이-브이 캐시), MoE (전문가 혼합 모델)와 같은 추론 최적화 기술의 세부 설계에 있습니다. 따라서 GPT (Generative Pre-trained Transformer) 계열이든 Gemini (제미나이), Claude (클로드) 계열이든 같은 Transformer (트랜스포머) 기반의 LLM이라 할지라도, 이처럼 다양한 핵심 요소들의 조합과 최적화에 따라 각 모델은 고유한 강점과 사용 시나리오를 가지게 됩니다. 단일 모델명에 얽매이기보다는 '무엇이 이 LLM의 성능과 특성을 가르는 핵심 요소인가?'라는 질문을 던지고 그 답을 이해하는 것이, LLM 입문자가 이 강력한 기술을 똑똑하게 활용하고 발전하는 AI 시대에 발맞춰 나가는 첫걸음이 될 것입니다.