개념·용어
-
 개인 AI Character Chatbot 비교
개인 AI Character Chatbot 비교크랙(wrtn.ai)은 Claude 3 기반의 자유형 시뮬레이션과 일부 NSFW 콘텐츠를 지원하며, 장기 대화에 유리한 출력량 기반 요금제를 제공합니다. 초기 캐릭터 챗봇 서비스는 ELIZA와 Replika에서 시작되었으며, 2022년 이후 LLM 기반 챗봇 기술이 상용화되면서 다양한 플랫폼이 등장했습니다. 주요 비교 항목으로는 사용자 정의 캐릭터, NSFW 지원, 음성·이미지 통합 등이 있으며, 예시로는 스티브 잡스 캐릭터를 만드는 방법이 포함되어 있습니다.
-
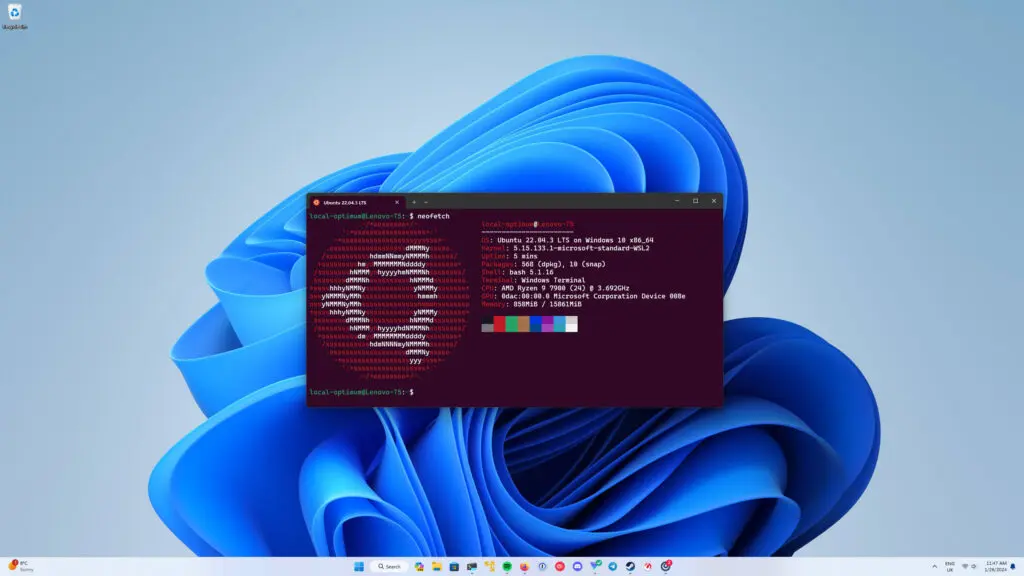 OS: Windows WSL2에서의 CLI 환경
OS: Windows WSL2에서의 CLI 환경CLI(명령줄 인터페이스)는 텍스트 기반의 명령어 입력을 통해 시스템과 상호작용하는 방식으로, Bash, CMD, PowerShell과 같은 다양한 셸이 있다. WSL2는 Windows 11에서 Linux 환경을 제공하며, WSLg를 통해 별도의 X 서버 없이도 Linux GUI 앱을 실행할 수 있는 기능을 지원한다. 이를 통해 Docker Desktop 설치 시 자동으로 WSL2가 활성화되며, 사용자는 GUI 구성 요소를 수동으로 설치하지 않고도 Linux 앱을 사용할 수 있다.
-
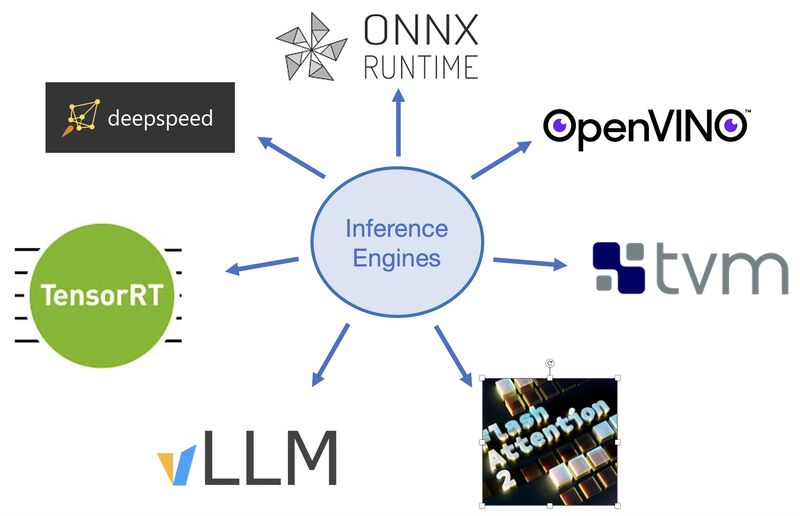 LLM 추론 엔진
LLM 추론 엔진대규모 언어 모델(LLM)을 구동하기 위한 LLM 추론 엔진은 메모리 로드, 계산 수행, 결과 생성 과정을 관리한다. LLM 추론 엔진은 PyTorch 기반, vLLM 기반, Ollama C++ 기반의 세 가지 주요 계열로 나뉘며, 각각 연구 개발, 대규모 처리, 제한된 리소스 환경에 최적화되어 있다. PyTorch는 유연한 개발을 지원하고, vLLM은 고속 처리에 적합하며, Ollama는 경량화된 모델 실행에 특화되어 있다.
-
 AI Wrapper - Thin vs Thick
AI Wrapper - Thin vs Thick대규모 언어 모델의 발전에 따라 도메인 특화형 AI 도구가 주목받고 있으나, 실제로는 목적 중심 설계가 중요하다. 사용자의 최상위 동기는 생산성 증대이며, AI Wrapper는 얇고 광범위한 구조에서 목적과 작업 형식에 따라 두꺼운 구조로 진화해야 한다. Formal Task와 Informal Task로 나누어 각각의 역할과 작업 형식을 제안하며, 진정한 목적 지향의 Thick Wrapper 구현을 목표로 한다.
-
 LLM: Google Gemini 접근 방식별 비교
LLM: Google Gemini 접근 방식별 비교Google Gemini의 접근 방식 비교: Gemini API는 개발자용 빠른 프로토타이핑에 적합하고, Gemini CLI는 터미널 기반 상호작용을 지원하며, Vertex AI API는 기업용 AI 플랫폼으로 보안과 데이터 거버넌스가 강점이다. 각 서비스는 인증 방식, 대상, 인프라 설정, 요금제 특징에서 차이를 보인다.
-
 데이터 수집 및 자동화 도구들
데이터 수집 및 자동화 도구들AI 기반 데이터 분석의 프로세스는 데이터 수집, LLM 분석, 결과 저장 및 게시, 자동 반복 실행으로 구성됩니다. 자료 분석 도구는 코드 기반과 No-code/FaaS 도구로 나뉘며, 개인 실습과 빠른 프로토타이핑을 위한 추천 조합이 제시됩니다.
-
 Dataset 데이터 제공 방식에 따른 데이터 수집 전략
Dataset 데이터 제공 방식에 따른 데이터 수집 전략웹페이지의 데이터 제공 방식에 따라 웹 크롤링과 웹 스크레이핑을 구분하고, 정적 페이지는 SSR로, 동적 페이지는 CSR 또는 하이브리드로 처리하는 효율적인 수집 방법을 제시한다. DevTools를 통해 구조를 식별한 후, 적절한 도구와 방법을 선택하여 최소 비용과 최대 안정성을 달성하는 것이 중요하다. 대규모 수집은 Scrapy로 파이프라인화하고, 배포는 Docker 컨테이너를 활용하는 것이 효율적이다.
-
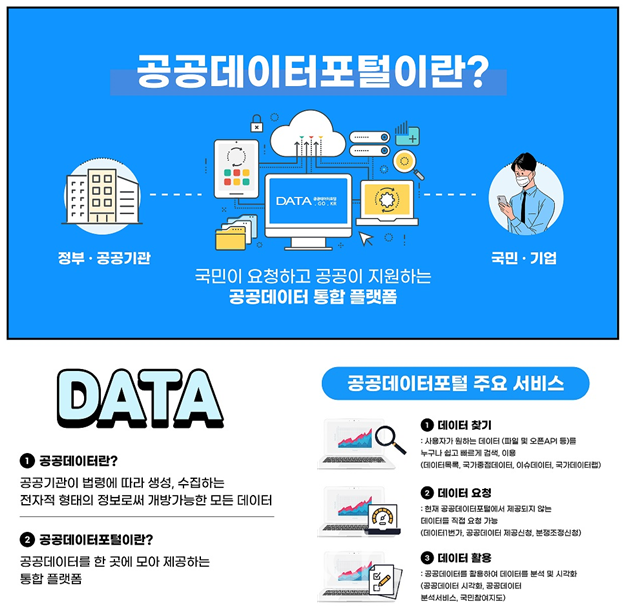 Dataset - 데이터 분석용 무료 공개 Dataset
Dataset - 데이터 분석용 무료 공개 Dataset무료 공개 데이터셋은 데이터 분석과 AI 모델 개발에 필수적이며, 포털 사이트형, 정부기관형, 학술자료형으로 나뉩니다. 포털 사이트형은 실시간 관심도 분석에 유용하고, 정부기관형은 다양한 공공 데이터를 제공하여 정책 연구와 창업 아이템 발굴에 활용됩니다. 학술자료형은 신뢰성 있는 연구 자료를 찾는 데 필수적입니다.
- LLM Ecosystem 현황 (2025년)
글로벌 AI LLM 응용 산업은 단일 LLM, 다중 LLM 오케스트레이션, 다중 앱 오케스트레이션으로 나뉘며, 한국은 투자자들이 단기 ROI에 집중하고 기술 난이도가 낮음에도 불구하고 혁신으로 포장하고 있다. 주요 기업으로는 Wrtn, Upstage, TwelveLabs 등이 있으며, AI 반도체 분야에서도 Furiosa AI와 DeepX가 두각을 나타내고 있다.
-
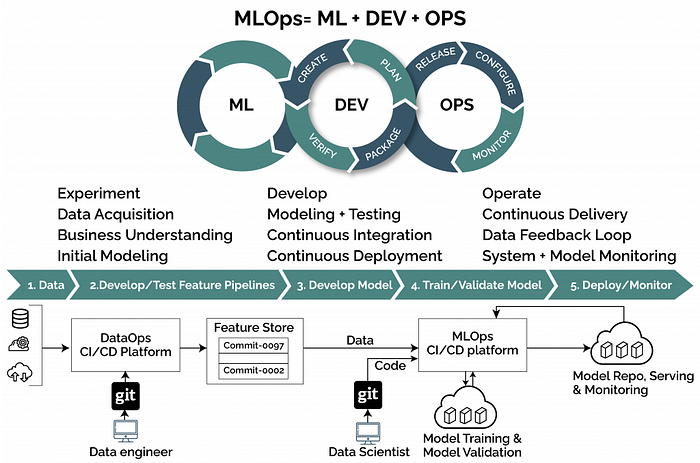 DevOps, MLOps, LLMOps, Agent AI 개념 및 추천 도구들
DevOps, MLOps, LLMOps, Agent AI 개념 및 추천 도구들DevOps, MLOps, LLMOps, 및 Agent AI의 개념과 도구를 설명하며, 각 계층의 핵심 개념과 특징을 정리하였다. DevOps는 소프트웨어 개발 및 운영의 통합을, MLOps는 머신러닝 모델의 자동화 및 관리, LLMOps는 대형 언어 모델의 특화된 운영을 다룬다. 다양한 오픈소스 및 상용 도구들이 소개되며, LLM을 활용한 협업 및 웹 자동화 도구도 포함된다.
- prompt: Engineering 기초
프롬프트 엔지니어링의 핵심 요소는 목표, 역할, 맥락, 지침, 어조, 대상 독자, 정보를 포함하여 AI에게 명확한 사고의 틀을 제공하는 것입니다. 연쇄적 사고 전략을 통해 단계별로 정보를 누적하여 분석하고, 각 단계에서 구체적인 목표와 지침을 설정하여 최적의 결과를 도출하는 방법을 설명합니다.
-
 Deployment Platform 비교
Deployment Platform 비교Firebase PaaS, Supabase PaaS, 및 Node.js/Express + PostgreSQL의 비교를 통해 가격, 서버 관리, 인프라 확장성, 모니터링, 배포, 백엔드 런타임, 서버리스 기능, 데이터베이스, ORM 접근, 실시간 기능, 인증, 권한 관리, 파일 저장소, 프론트엔드 프레임워크, 텍스트 에디터 등의 차이점을 정리하였다.
- AI Orchestration - CrewAI vs. LangChain
CrewAI와 LangChain의 비교에서 CrewAI는 빠르게 성장하는 생태계로, 단순성과 협업 중심의 설계를 강조하며, 오픈 소스에서 유료 API로 확장 가능성을 지니고 있다. 반면 LangChain은 LLM 생태계의 표준으로, 높은 진입 장벽과 복잡한 구조를 가지고 있으며, 유료 클라우드 플랫폼으로 연결되는 잠금 구조를 특징으로 한다. 기술적으로 CrewAI는 역할 기반 Crews와 이벤트 중심의 흐름 제어를 사용하고, LangChain은 상태 기반 에이전트 흐름과 체인 기반 함수 흐름을 채택한다.
-
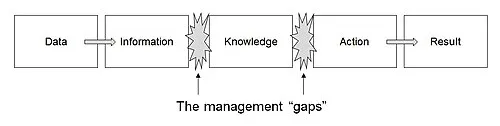 Dataset - LLM 학습용 corpus 목록 (2025)
Dataset - LLM 학습용 corpus 목록 (2025)2025년 LLM 학습용 데이터셋 목록에는 영어와 한국어의 대표 데이터셋이 포함되어 있으며, 각 데이터셋의 라이선스, 주체, 언어 및 특징, 내용 품질이 정리되어 있다. 영어 데이터셋으로는 English Wikipedia, Wiki-40B, CC-News 등이 있으며, 한국어 데이터셋으로는 KorQuAD, Korean Wikipedia, TED Talks 등이 있다. 각 데이터셋은 품질과 특성에 따라 분류되어 있다.
-
 SNS 플랫폼 핵심 특성 비교
SNS 플랫폼 핵심 특성 비교다양한 SNS 플랫폼의 핵심 특성을 비교한 표에는 YouTube, TikTok, Facebook, Instagram, Threads, Twitter, Discord, LinkedIn, Reddit, Pinterest, Circle.so의 포맷 구조와 콘텐츠 특성이 정리되어 있으며, 각 플랫폼에 적합한 콘텐츠 유형이 제시되어 있습니다.
- LLM 런타임 병목, CUDA 종속성 (ONNX와 ROCm)
딥러닝과 대규모 언어 모델은 NVIDIA의 CUDA 생태계에 의존하지만, 이는 런타임에서의 기술적 병목을 초래한다. ONNX 형식은 플랫폼 독립성을 제공하려고 하지만, 변환 손실과 성능 최적화의 한계가 있다. ROCm은 CUDA 대안을 제공하나, 운영체제 제약과 생태계 미성숙으로 인해 실질적인 선택지로 인식되기 어렵다. 결국, 개발자 경험과 생태계의 성숙도가 기술 선택의 핵심 요소임을 강조한다.
- AI Transformer Model vs Deep Learning Model
딥러닝 모델과 트랜스포머 모델은 AI 혁신의 중심에 있으며, 각각의 특성과 장점이 다릅니다. 딥러닝은 인공신경망을 기반으로 하여 다양한 분야에서 성과를 거두었고, LSTM은 시계열 데이터 처리에 강점을 보입니다. 반면, 트랜스포머 모델은 어텐션 메커니즘을 통해 빠른 학습 속도와 장거리 의존성 포착 능력을 제공합니다. 그러나 특정 문제의 특성, 자원 효율성, 성과와 실용성 등을 고려할 때 여전히 기존 딥러닝 모델이 선호되는 경우가 많습니다. 다양한 모델이 각자의 장점을 가지고 AI 앱 개발에 활용되고 있습니다.
- LLM 시대의 NPU HW 전쟁 (2025년)
대규모 LLM의 확산으로 메모리 병목이 주요 제약으로 부각되며, INT4 양자화 및 LoRA와 같은 최신 최적화 기술이 필요하다. NVIDIA는 강력한 CUDA 생태계로 서버 시장을 지배하고, Qualcomm은 저전력 엣지 추론에 특화되어 있으며, 한국 팹리스는 글로벌 경쟁력 부족으로 어려움을 겪고 있다. LLM 시대의 경쟁은 단일 연산 코어 혁신이 아닌 SW-HW-모델 통합 최적화에 의해 결정된다.
-
 Cloud Computing과 Web App
Cloud Computing과 Web App클라우드 컴퓨팅은 웹 애플리케이션 개발의 비효율성을 극복하기 위해 발전하였으며, 자원 낭비 문제, 높은 진입 장벽, 분산 협업 수요 증가에 대응합니다. 클라우드 기반으로 자원을 임대하여 사용하는 방식으로, 다양한 웹 애플리케이션과 개발 플랫폼이 이를 채택하고 있습니다. 장점으로는 디바이스 독립성, 초기 비용 없음, 유지보수 부담 감소, 온디맨드 확장성, 글로벌 협업 최적화가 있으며, 단점으로는 벤더 종속성, 인터넷 의존성, 보안 및 프라이버시 우려가 있습니다.
-
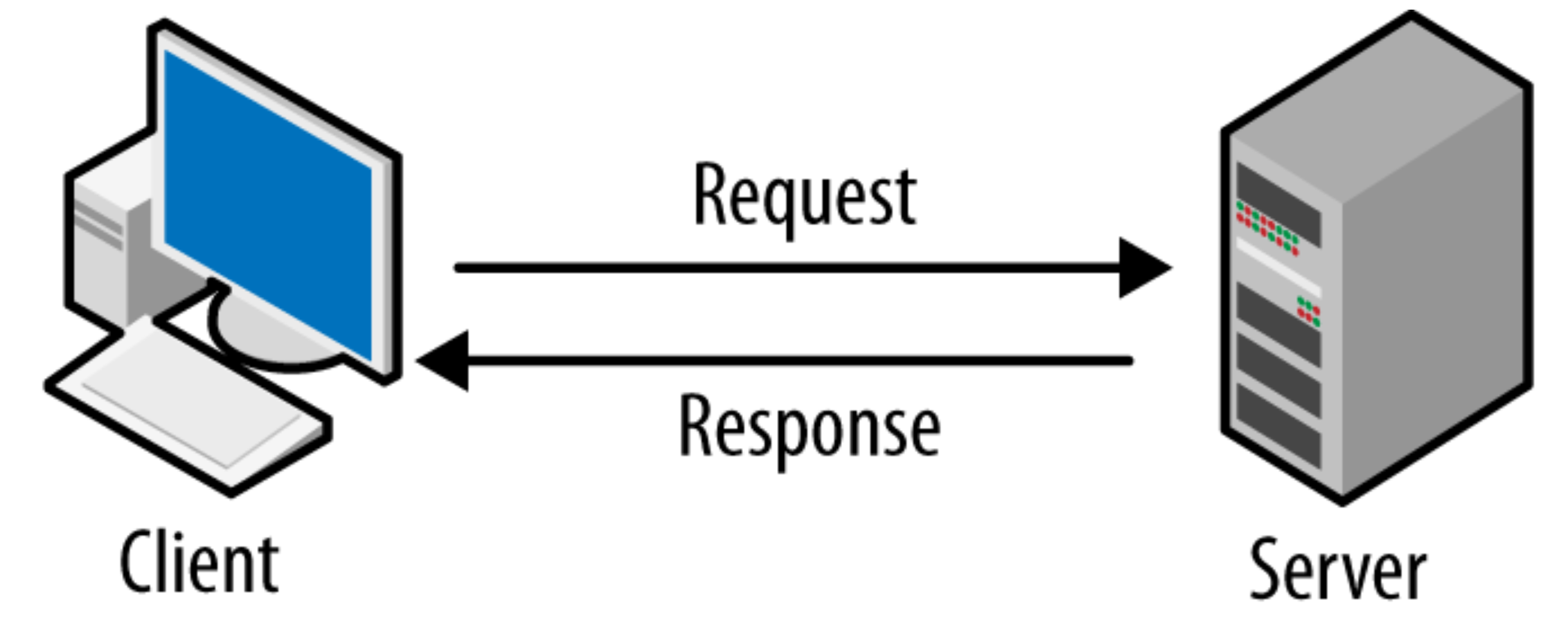 개념: Cloud computing Web App 기초 원리
개념: Cloud computing Web App 기초 원리클라이언트-서버 모델은 요청과 응답의 관계를 통해 작동하며, API, 프로토콜, 요금 구조에 기반한다. 기술의 진화는 Unix 시스템에서 클라우드 컴퓨팅으로 발전하였고, 클라우드 서비스는 IaaS, PaaS, SaaS의 계층 구조로 구성되어 있다. 각 계층은 물리적 자원, 추상화된 실행 환경, 최종 소프트웨어를 제공하며, 경제적 요소와 수요-공급 관계를 반영한다.