개념·용어
-
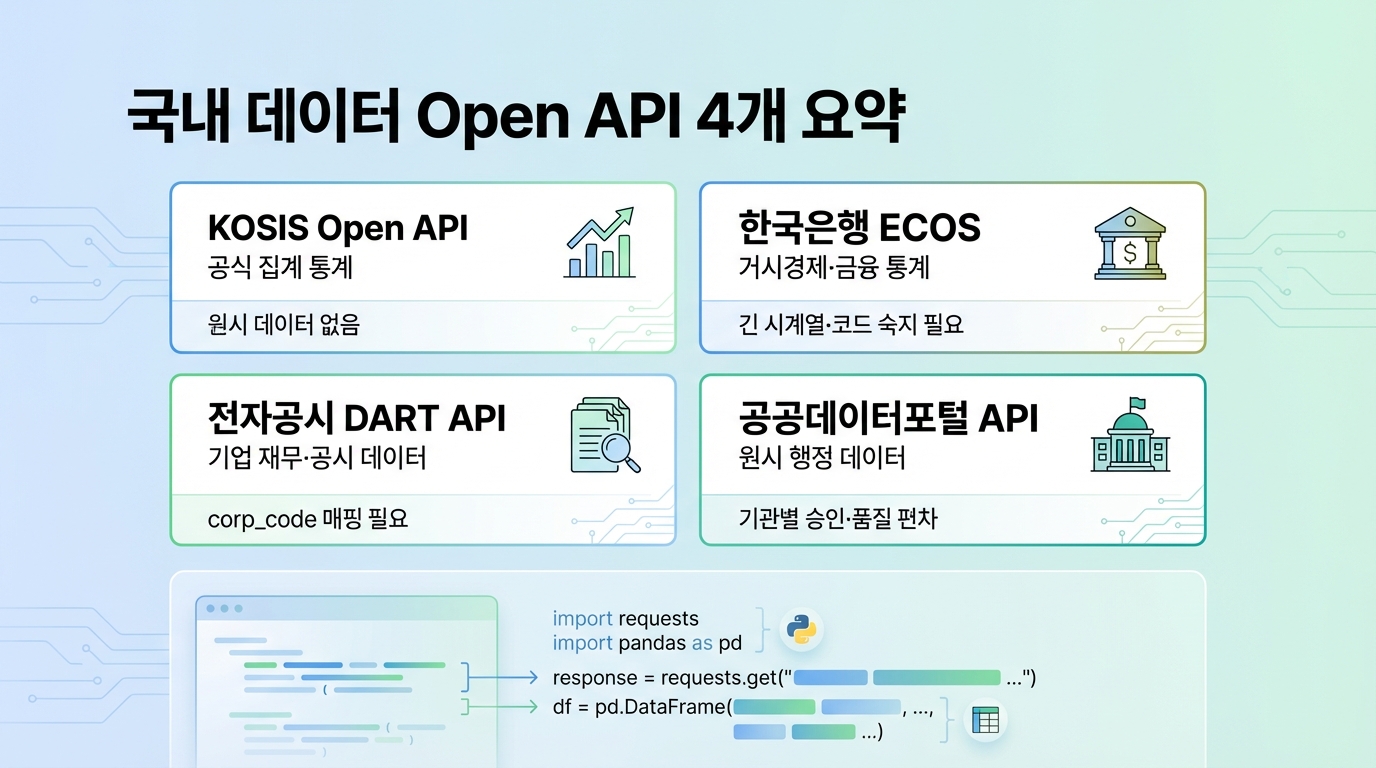 Dataset 통계데이터: 무료 공식·행정 통계 데이터 API
Dataset 통계데이터: 무료 공식·행정 통계 데이터 API국내 데이터 Open API 4개에 대한 설명: KOSIS Open API는 공식 집계 통계에 접근 가능하나 원시 데이터는 없음; 한국은행 ECOS는 거시경제 통계 제공, 통계코드 숙지가 필요; DART API는 기업의 전자공시 자료에 접근 가능하지만 기업코드 매핑이 필요; 공공데이터포털 API는 원시 행정 데이터를 제공하나 기관별 승인이 필요하다. 각 API에 대한 Python 호출 예제도 포함되어 있다.
-
 Dataset - 뉴스 기사 데이터 예시
Dataset - 뉴스 기사 데이터 예시Naver News에서 크롤링한 27,400개의 뉴스 기사를 포함한 데이터셋은 IT와 경제 분야에 중점을 두며, 개인화된 뉴스 대시보드 웹 앱 구현을 목표로 한다. 데이터는 정치성향 분류를 위한 NLP 모델 학습에 활용되며, 최종적으로 뉴스 수집, 전처리, 분류, 점수화 및 요약에 중점을 둔다.
- 상품홍보대행: 자료수집용 사이트 목록
랭킹 검색어와 뉴스 기사를 수집하기 위한 방법으로, 판다랭크, 블랙키위, 시그널, Zum 등의 플랫폼을 활용하여 인기 키워드를 분석하고, 네이버뉴스와 같은 사이트에서 다양한 뉴스 기사를 필터링 및 정렬하는 방법을 제시한다. 데이터 수집 방향의 장단점도 설명하며, 네이버뉴스의 세부 URL과 선택자 정보를 제공한다.
-
 블록체인 네트워크 속도 vs 안정성 vs 비용
블록체인 네트워크 속도 vs 안정성 vs 비용Ethereum은 안정성이 높지만 수수료가 비쌀 수 있으며, Solana는 빠르고 저렴하지만 생태계 영향을 고려해야 한다. Tron, BNB Chain, Avalanche는 속도와 비용의 균형을 제공하고, Polygon과 Arbitrum은 Ethereum과 호환성을 유지하면서 비용 절감을 실현한다.
-
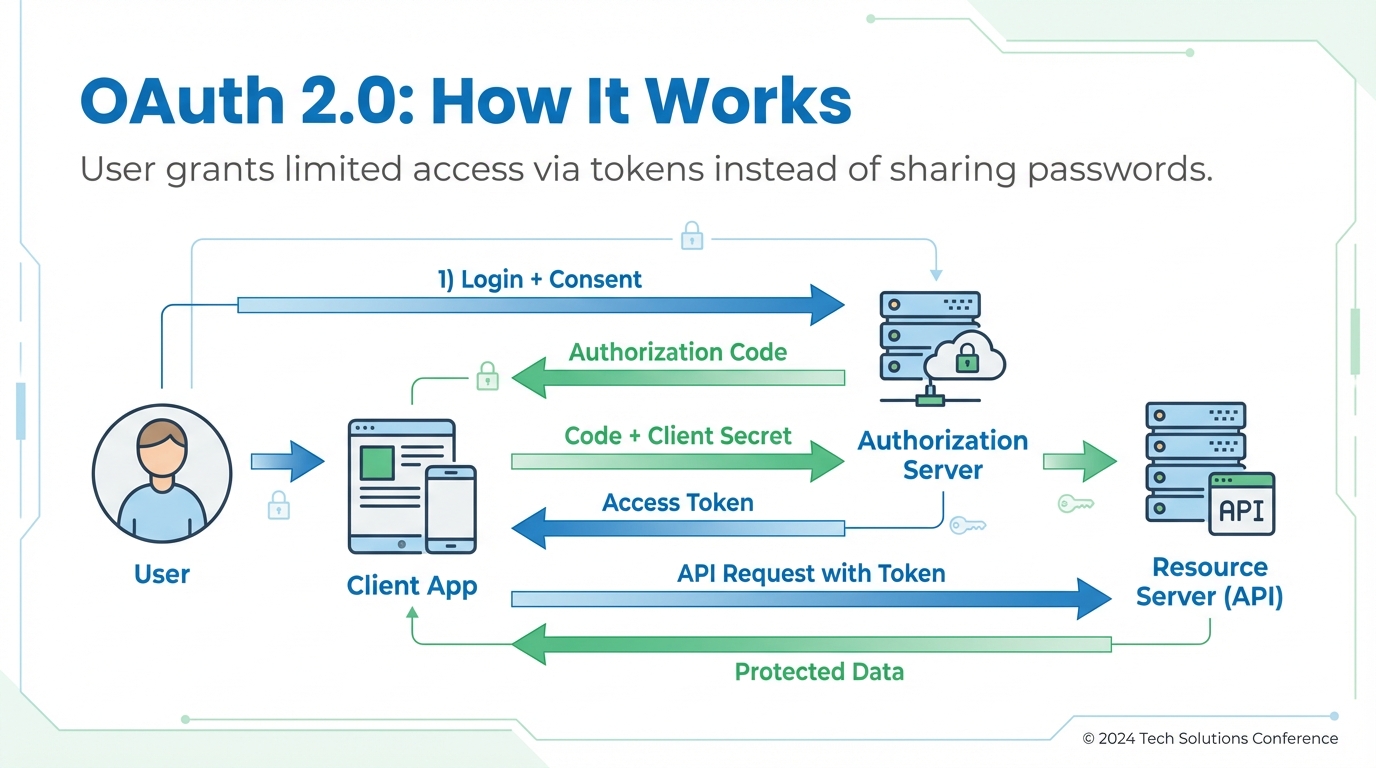 개념: OAuth 2.0 (Open Authorization, 공개 인증) 실행 원리
개념: OAuth 2.0 (Open Authorization, 공개 인증) 실행 원리OAuth 2.0은 사용자가 비밀번호 대신 Access Token을 사용하여 클라이언트 앱에 제한된 권한을 부여하는 인가 체계이다. 사용자는 인증 서버에서 본인 인증 후 권한 요청에 동의하면, 클라이언트는 Authorization Code를 통해 Access Token을 발급받아 자원 서버에 접근한다. 주요 구성 요소로는 사용자, 클라이언트, 인증 서버, 자원 서버가 있다.
- 공감형콘텐츠 제작의 핵심: 인간의 서사·구성·어조
공감형 콘텐츠 제작은 AI와 인간의 협업을 통해 주제를 선정하고, 제안서를 작성하며, 최종 검수를 거쳐 완성된다. 정치, 법률, 경제 분야의 콘텐츠 제작 프레임워크는 사건의 배경, 사실 정리, 대립 분석, 합리적 판단 및 피드백 단계를 포함한다. 각 단계에서 정량적 데이터와 정성적 내러티브를 혼합하여 접근하는 것이 중요하다.
- Market Research 이론
GTM, TAM, SAM, SOM 개념을 통해 시장 세분화의 중요성을 강조하며, 3C 분석(고객, 경쟁자, 회사)과 SWOT 분석(강점, 약점, 기회, 위협)을 통해 비즈니스의 세분화된 시장과 집중할 제품을 찾는 방법을 설명한다. STP(세분화, 타겟팅, 포지셔닝)도 강조된다.
-
 JAMstack 스타일
JAMstack 스타일JAMstack 스타일은 Headless CMS, API, 정적 사이트 생성기를 결합하여 CMS, API, 프론트엔드를 완전히 분리하고 유지보수성을 높이며, 백엔드는 데이터 API로 작동하고 프론트엔드는 이를 소비하며, 정적인 HTML을 미리 생성하여 CDN에서 배포하는 구조입니다. Supabase와 Firebase는 이러한 스타일에 적합한 도구입니다.
-
 Web App 기술 스택-클라우드 서비스
Web App 기술 스택-클라우드 서비스웹 애플리케이션 기술 스택에는 프론트엔드 서버(HTML, CSS, JS, React, Next.js 등), 백엔드 서버(FastAPI, Express, Flask 등), 데이터베이스(SQL, NoSQL 등), 그리고 오케스트레이션 레이어가 포함됩니다. 다양한 호스팅 제공업체로는 n8n Cloud, Google Cloud Functions, Vercel, Supabase 등이 있으며, 정적 프론트엔드와 서버리스 백엔드를 결합한 예시로 Next.js와 Google Cloud Functions를 들 수 있습니다. Workflow-as-a-Service 도구 비교에서는 Make, n8n Cloud, Apify, Cloudflare Workers, Google Cloud Functions 등이 언급되며, 각 플랫폼의 비용, 사용 편의성, 속도 및 특징이 정리되어 있습니다.
-
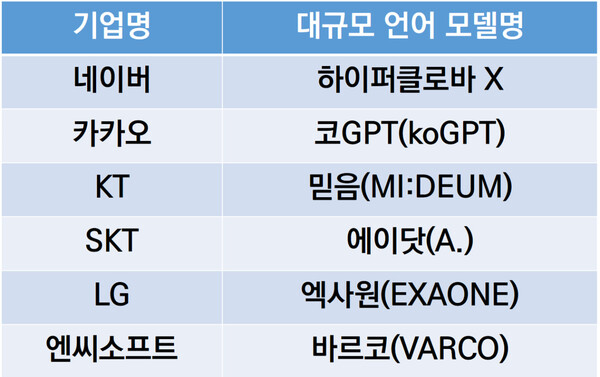 개인 AI Companion 튜닝용 한국어 LLM
개인 AI Companion 튜닝용 한국어 LLM한국어 LLM의 발전은 2023년부터 시작되어, SKT의 KoGPT와 Naver의 HyperCLOVA가 상업적 시장을 개척하였다. 다양한 경량 모델과 클라우드 서버 환경이 등장하며, 개인이 로컬 환경에서 LLM을 실행하고 튜닝할 수 있는 가능성이 열렸다. 여러 모델의 비교와 추천 호스팅 정보, 튜닝 전략이 제시되었다.
-
 Agentic AI (Browser-use LLM) 비교
Agentic AI (Browser-use LLM) 비교Genspark AI는 웹 탐색과 자동화 기능이 뛰어난 브라우저 네이티브 LLM 에이전트로 추천되며, 2023년부터 LLM 기반 에이전트들이 웹 자동화의 패러다임을 변화시키고 있다. 주요 대안으로는 ChatGPT Agent Mode, Skyworks AI, Manus AI 등이 있으며, 각 제품은 실시간 브라우저 탐색, 협업 중심 시스템, Gmail 및 Jira와의 통합 등 다양한 기능을 제공한다.
-
 AI Prompt Engineering 방법
AI Prompt Engineering 방법프롬프트 엔지니어링을 위한 도구와 구조를 제안하며, 사용자 입력을 명확히 다듬고 최종 답변을 생성하는 2단계 프로세스를 소개한다. 다양한 역할에 따라 AI의 응답 톤과 길이를 조정할 수 있는 방법도 설명된다.
-
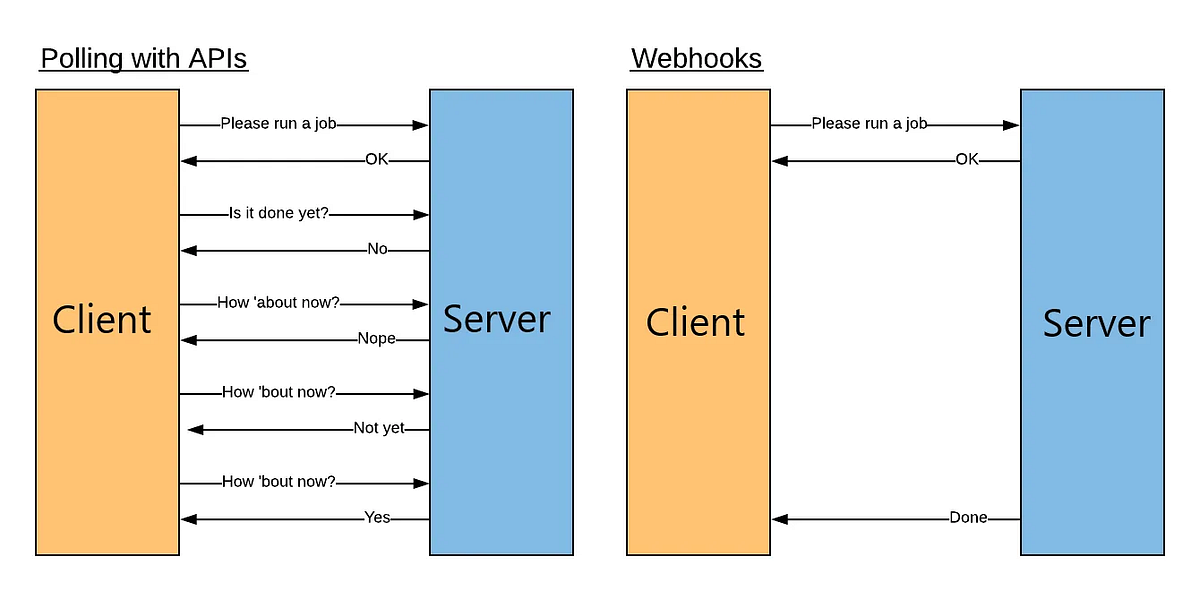 API: Web Server(Proxy, Reverse Proxy), Webhook (웹훅)
API: Web Server(Proxy, Reverse Proxy), Webhook (웹훅)Proxy와 Reverse Proxy는 클라이언트와 서버 간의 익명성과 성능/보안을 제공하는 기술로, Proxy는 클라이언트의 신원을 숨기고, Reverse Proxy는 서버의 구조를 보호합니다. 웹훅은 특정 이벤트 발생 시 발신 서버가 수신 서버에 HTTP 요청을 보내는 방식으로, JSON 포맷을 사용하여 데이터를 전달합니다. 웹훅은 실시간 알림이 가능하고, Polling 방식에 비해 효율적입니다.
- API: Domain, DNS, A Record, CNAME
도메인 등록기관은 도메인 이름을 구매하고 소유권을 관리하며, DNS 서버는 도메인 이름을 IP 주소로 변환하는 역할을 한다. A 레코드는 도메인을 IP 주소에 직접 연결하고, CNAME 레코드는 다른 도메인의 별칭을 지정한다. Cloudflare를 통해 DNS 관리를 이전하면 HTTPS 인증서 자동화와 무료 CDN, 보안 기능을 활용할 수 있다. DNS 설정 예시와 이전 방법도 제공된다.
-
 Cloud MLOps - AWS, GCP 서비스로 이해하기
Cloud MLOps - AWS, GCP 서비스로 이해하기AI 도구 개발을 위한 MLOps와 LLM Wrapper의 개념을 설명하며, AWS와 GCP의 구조를 비교한다. AWS에서는 EC2, S3, SageMaker 등을 활용하고, GCP에서는 Firebase와 Vertex AI를 중심으로 한 흐름을 제시한다. CI/CD 파이프라인을 통해 자동화된 배포 및 테스트를 강조하며, 각 플랫폼의 구성 요소와 역할을 상세히 설명한다.
-
 소프트웨어 사용권 (Software Licenses)
소프트웨어 사용권 (Software Licenses)소프트웨어 사용권은 보통 5가지 유형으로 분류되며, 각각의 특성과 대표 기술이 설명된다. 주요 유형은 Proprietary, GPL, LGPL, Permissive, Public Domain으로, 각 라이선스의 소스 공개 여부, 상업적 이용 가능성, 동일 라이선스 강제 여부가 다르다. 또한, 다양한 소프트웨어와 그에 따른 라이선스 유형이 나열되어 있다.
-
 SaaS for Community Membership
SaaS for Community MembershipSaaS 플랫폼 비교: Slack, Reddit, Facebook Groups, Discord, Circle.so, Bettermode, Hivebrite, Mighty Networks, GroupApp, Kajabi, Discourse의 주요 기능, 사용 사례 및 가격을 정리한 표. 각 플랫폼은 특정 커뮤니티 요구에 맞춰 다양한 기능과 가격 옵션을 제공한다.
-
 연산 실행 계층 구조 - Python vs. C
연산 실행 계층 구조 - Python vs. C연산 실행 계층은 상위 계층에서 하위 계층으로 정렬되며, Python은 인터프리터를 통해 간접적으로 실행되고 C는 컴파일러를 통해 직접 실행된다. Python은 소스코드를 바이트코드로 변환한 후 실시간으로 해석하여 OS를 호출하고, C는 기계어로 변환된 바이너리 파일을 OS를 통해 CPU에 직접 전달하여 실행된다. 각 언어의 실행 효율과 구조의 차이가 강조된다.
-
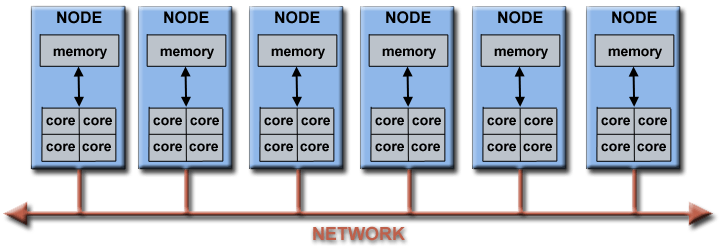 연산 실행 계층 구조 - LLM, 딥러닝, 병렬
연산 실행 계층 구조 - LLM, 딥러닝, 병렬2025년 기준의 LLM과 관련된 하드웨어, 주요 라이브러리, 병렬 연산 SDK에 대한 개요를 제공하며, NVIDIA의 CUDA 생태계와 다양한 기술 계층을 설명합니다. PyTorch, TensorFlow, JAX와 같은 프레임워크가 LLM 연구 및 개발에 핵심적인 역할을 하고 있으며, 각 프레임워크의 특징과 사용 사례를 비교합니다.
-
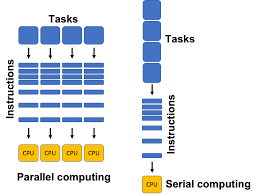 연산 실행 병렬처리법 (언어별 예시)
연산 실행 병렬처리법 (언어별 예시)CPU와 GPU의 병렬 연산 차이를 설명하며, C, C++, Java, Python 언어로 100 × (1+2) 연산을 수행하는 예시를 제공한다. CPU는 범용 작업에 최적화된 반면, GPU는 대규모 병렬 연산에 적합하다. Python에서는 joblib와 Numba를 이용한 CPU 및 GPU 병렬 처리 방법을 설명하고, CUDA 라이브러리를 사용한 GPU 활용 예시도 포함된다.