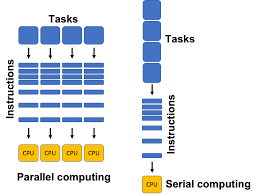
병렬연산 (CPU vs. GPU)
- CPU: 뛰어난 성능의 몇개의 core 들. 범용 작업이나 복잡한 연산에 최적화 됨.
- GPU: 떨어지는 성능의 수많은 core 들. 단순 반복적인 대규모 병렬연산에 최적화 됨.
- '왠만한' 수학 연산은 CPU를 이용한 병렬 연산으로 처리할 수 있으나 (예: C/C++/Fortran에서 OpenML API를 이용하거나, Python에서
jobliblibrary 이용), LLM의 등장으로 GPU를 이용한 병렬 연산의 필요성이 압도적으로 커짐.
100 × (1+2) = 300을 수행
C 언어
c
#include <stdio.h>
int main() {
int a = 1, b = 2;
int result = a + b;
printf("1 + 2 = %d\\n", result);
// 여러 번 반복
int sum = 0;
for (int i = 0; i < 100; i++) {
sum += a + b;
}
printf("100 * (1 + 2) = %d\\n", sum);
return 0;
}
C++ 언어
c++
#include <iostream>
using namespace std;
int main() {
int a = 1, b = 2;
int result = a + b;
cout << "1 + 2 = " << result << endl;
// 여러 번 반복
int sum = 0;
for (int i = 0; i < 100; ++i) {
sum += a + b;
}
cout << "100 * (1 + 2) = " << sum << endl;
return 0;
}
Java 언어
java
public class Main {
public static void main(String[] args) {
int a = 1, b = 2;
int result = a + b;
System.out.println("1 + 2 = " + result);
// 여러 번 반복
int sum = 0;
for (int i = 0; i < 100; i++) {
sum += a + b;
}
System.out.println("100 * (1 + 2) = " + sum);
}
}
Python 언어
python
a = 1
b = 2
result = a + b
print("1 + 2 =", result)
# 여러 번 반복
sum_result = 0
for _ in range(100):
sum_result += a + b
print("100 * (1 + 2) =", sum_result)
Python 언어 library
| 비교 항목 | CPU 기반 (joblib, multiprocessing 등) | GPU 기반 (Numba.cuda, PyCUDA 등) |
|---|---|---|
| 연산 단위 | 수십~수백 개 코어, 일반적인 병렬성 | 수천~수만 개 스레드, 대규모 벡터 연산 |
| 적합한 작업 | 분기 구조가 많은 일반 계산, 로직 분산 | 반복 연산이 많은 행렬/벡터, 수치해석 |
| 코드 복잡도 | 낮음 (Python 표준 또는 joblib) | 높음 (커널 작성 필요) |
| 하드웨어 의존성 | 거의 없음 (모든 CPU에서 가능) | NVIDIA GPU 필수 (CUDA 기반이라면) |
| 대표 기술 | joblib, concurrent.futures, Dask | Numba, PyCUDA, CuPy |
Python 언어 CUDA library로 GPU 사용
1 + 2 연산을 GPU에서 100개 쓰레드로 병렬 수행하고, 결과 배열을 CPU로 복사한 뒤 합산 → 100 * (1 + 2) = 300
Numba: Python 코드를 JIT(Just-In-Time) 컴파일하는 라이브러리. CPU 병렬처리는 @njit(parallel=True) decorator. GPU 병렬처리는 NVIDIA CUDA SDK 기반 @cuda.jit decorator.
python
from numba import cuda
import numpy as np
# GPU 커널 정의
@cuda.jit
def add_kernel(a, b, out):
idx = cuda.grid(1)
if idx < out.size:
out[idx] = a + b
# 입력 데이터
n = 100
a, b = 1, 2
result_gpu = np.zeros(n, dtype=np.int32)
# GPU 메모리 할당
d_out = cuda.to_device(result_gpu)
# 블록/그리드 설정
threads_per_block = 32
blocks_per_grid = (n + threads_per_block - 1) // threads_per_block
# 커널 실행
add_kernel[blocks_per_grid, threads_per_block](a, b, d_out)
# 결과 복사
result_gpu = d_out.copy_to_host()
# 전체 합계 계산
total = np.sum(result_gpu)
print("100 * (1 + 2) =", total)