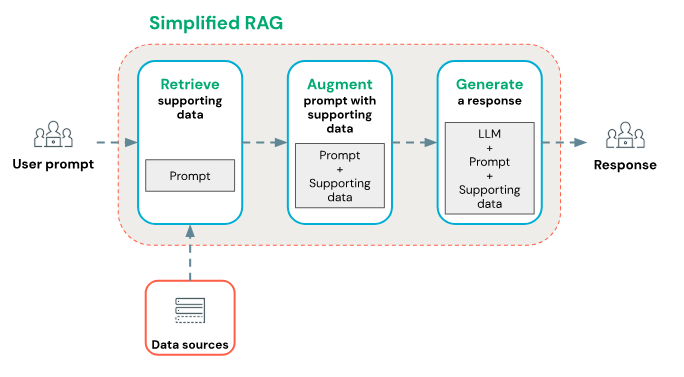
대규모 언어 모델(LLM, Large Language Model)은 단독으로도 강력하지만, 외부 지식 기반을 실시간으로 검색하여 응답 품질을 높이는 RAG (Retrieval-Augmented Generation) 기술과 결합되면 활용 범위가 크게 확장됩니다. 본 글은 GPT (Generative Pre-trained Transformer)를 포함한 LLM 개념의 기초를 정리하고, 검색 기반 학습 계열의 핵심 흐름인 Document Loading → Chunking → Embedding → Vector Store → Retrieval → LLM → 응답 생성 단계를 설명합니다. 또한 RAG를 구현할 때 가장 널리 쓰이는 두 오픈소스 프레임워크인 LlamaIndex (구 GPT Index)와 LangChain의 특징과 차이점을 비교하고, 사용 목적에 따른 적합한 선택 가이드를 제시합니다.
서론
GPT (Generative Pre-trained Transformer)는 2017년 Google (구글) 연구진이 발표한 Transformer (트랜스포머) 아키텍처를 기반으로 대규모 데이터셋을 사전 학습한 대표적 생성형 인공지능 모델입니다. GPT는 LLM (Large Language Model)의 대표 사례이며, LLM은 다시 Machine Learning Model (ML, 머신러닝 모델) 계열에 포함됩니다. 기존의 언어 모델은 문자열(string)을 입력받아 문자열(string)을 출력했지만, 최근의 LLM은 Chat Interface (대화형 인터페이스)를 통해 메시지 목록을 입력받고 메시지를 출력하는 형태로 발전했습니다. 그러나 사전 학습된 LLM은 훈련 시점 이후의 새로운 정보나 외부 데이터에 대한 실시간 접근성이 떨어집니다. 이를 보완하기 위해 등장한 기술이 RAG (Retrieval-Augmented Generation)입니다. RAG는 외부 문서를 검색(Retrieval)해 관련 정보를 가져온 뒤 이를 LLM이 생성(Generation) 단계에서 활용하도록 연결하는 구조로, 사실성(Factuality)을 높이고 최신성을 확보할 수 있습니다.
본론
1. RAG의 핵심 처리 흐름
RAG 시스템은 다음과 같은 단계를 거칩니다.
- Document Loading: PDF, HTML, Notion 등 다양한 원본 문서를 불러오기
- Chunking: 긴 문서를 LLM이 처리할 수 있는 단위로 분할
- Embedding: 문서 청크를 벡터로 변환하여 유사도 검색이 가능하도록 처리
- Vector Store: Embedding 결과를 벡터 데이터베이스에 저장
- Retrieval: 사용자의 질문(Query)에 맞는 문서 청크를 벡터 DB에서 검색
- LLM: 검색된 문서 내용을 기반으로 답변 생성
- 응답 생성: 최종 출력
2. 대표 오픈소스 프레임워크 비교
| 항목 | LlamaIndex (구 GPT Index) | LangChain |
|---|---|---|
| 목적 | Indexing과 Chunking 중심의 경량 RAG 프레임워크 | LLM 기반 복합 Workflow 구축용 범용 프레임워크 |
| 특징 | 문서 → Embedding → Index → Query Response 흐름 단순화 | LLM, Retriever, Memory, Agent 등을 유연하게 연결 |
| 장점 | Tree Index, Keyword Index 등 다양한 인덱스 구조 지원 | 문서 로더, 템플릿, Vector Store, 외부 API 연동 등을 체계적으로 지원 |
| 한계 | Workflow나 Agent 기능은 자체적으로는 약함 | 초보자에겐 불필요하게 복잡할 수 있음 |
| 활용 | 대규모 PDF/HTML/Notion 문서를 RAG로 연결하는 데 최적화 | End-to-end RAG, Agent 구성, Web Scraping + LLM 응답 등 |
3. 목적별 추천 가이드
| 사용 목적 | 추천 프레임워크 | 설명 |
| 간단한 QA 시스템 빠른 구축 | LlamaIndex | 낮은 진입 장벽, Chunk-Embed-Retrieve 흐름 학습에 적합 |
| 문서 기반 RAG 기본 구조 실습 | LlamaIndex | Index 구조와 벡터 검색 실습에 강점 |
| 복합 Workflow, API 연동 | LangChain | Retrieval + Summarization + External API까지 확장 가능 |
| Agent 기반 다중 도구 연계 | LangChain | Google (구글) Search, WolframAlpha 등 외부 툴 연동 |
결론
GPT (Generative Pre-trained Transformer)와 같은 LLM은 문장 생성에서 압도적 성능을 보여주지만, 최신 정보와 외부 지식을 실시간으로 다루기 위해서는 RAG (Retrieval-Augmented Generation) 기술이 필수입니다. LlamaIndex와 LangChain은 목적과 난이도에 따라 선택할 수 있는 대표 오픈소스 프레임워크로, 학습자가 Chunking, Embedding, Retrieval 과정을 직접 실습하며 LLM의 한계를 극복하는 방법을 이해할 수 있게 돕습니다. 초보 단계에서는 LlamaIndex로 시작해 Index 구조와 벡터 검색 원리를 익히고, 필요에 따라 LangChain으로 넘어가 복잡한 Workflow나 Agent 구조를 확장하는 것이 추천됩니다.