도메인 특화 대규모 언어 모델 (Domain-specific LLM): 미세조정 방식 (Fine-tuning)과 검색 증강 생성 방식 (RAG) 비교 분석
목표: chain of thought 처럼 variance를 줄이는게 아닌 방식으로, 어떻게 하면 llm 답변의 halluciation을 줄일 수 있을까?
서론
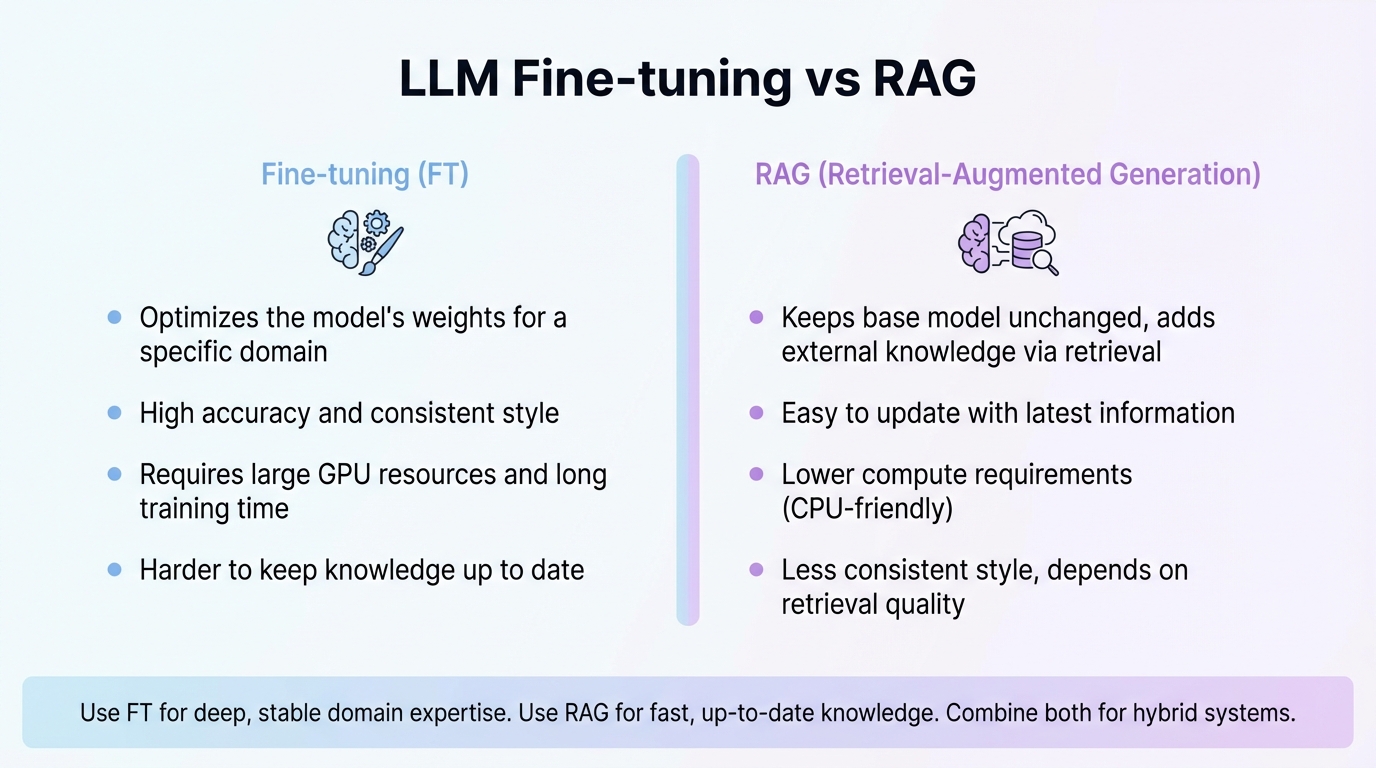
최근 인공지능 (Artificial Intelligence, AI) 분야에서 대규모 언어 모델 (Large Language Model, LLM)은 자연어 처리 (Natural Language Processing, NLP) 분야의 혁신을 이끌고 있다. 그러나 사전 학습된 LLM은 방대한 일반 데이터를 기반으로 학습되므로, 특정 도메인이나 최신 정보에 대한 응답 정확도가 낮을 수 있다. LLM을 특정 데이터에 맞춤화하는 방법은 크게 미세조정 기술(Fine-tuning)과 검색 증강 생성 기술 (Retrieval-Augmented Generation, RAG)으로 나눌 수 있다. 신속한 데이터 반영과 낮은 연산 자원이 요구되는 경우에는 RAG 방식이, 특정 데이터에 대한 높은 정확도와 모델의 영구적인 최적화가 필요한 경우에는 미세조정 방식이 효과적일 것이다.
미세조정 방식 (FT, Fine-tuning): 모델 자체의 지식과 특성을 최적화하는 방법
미세조정 방식 (Fine-tuning)은 기존에 학습된 대규모 언어 모델 (LLM)의 가중치 (weights)를 특정 목적에 맞는 데이터셋 (dataset)으로 미세 조정하는 방식이다. 이는 마치 기존의 방대한 지식 체계를 가진 전문가에게 특정 분야의 전문 서적을 집중적으로 학습시켜 해당 분야에 대한 심층적인 이해와 응답 능력을 강화하는 것과 유사하다. 이 방식은 LLM이 특정 데이터의 문체, 표현 방식, 그리고 핵심 정보를 내재화하도록 하여, 해당 도메인에 최적화된 응답을 생성할 수 있게 한다.
미세조정 방식의 주요 단계는 다음과 같다.
첫째, 특정 웹사이트 (예: Wikipedia)나 데이터 소스에서 필요한 데이터를 크롤링 (crawling)하고 정제하는 과정이 필요하다. 이 과정에서 Beautiful Soup, Scrapy, requests와 같은 라이브러리들이 활용되며, 수집된 데이터는 JSON, TXT, CSV 등의 표준 형식으로 변환되고 불필요한 정보가 제거된다.
둘째, 정제된 데이터를 Hugging Face datasets (허깅 페이스 데이터셋) 라이브러리를 활용하여 LLM이 학습할 수 있는 포맷 (예: .jsonl, .csv)으로 변환하며, tiktoken (틱토큰)이나 sentencepiece (센텐스피스)와 같은 도구를 사용하여 LLM과 호환되는 토큰 (token) 형식으로 전처리한다.
셋째, Llama, Mistral, Falcon과 같은 오픈소스 LLM을 선택하고, GPU (Graphics Processing Unit) 부담을 줄이기 위한 Low-Rank Adaptation (LoRA)와 같은 Parameter-Efficient Fine-Tuning (PEFT, 파라미터 효율적 파인튜닝) 기법을 활용하여 모델을 학습시킨다. Hugging Face의 transformers 라이브러리와 PEFT가 이 과정에서 핵심적인 역할을 한다.
넷째, Trainer API를 사용하거나 DeepSpeed, FSDP와 같은 분산 학습 (distributed training) 기법을 활용하여 파인튜닝을 실행한다. 마지막으로, 학습된 모델은 Hugging Face Model Hub에 배포하거나 FastAPI, Gradio 등을 이용하여 API (Application Programming Interface) 형태로 제공할 수 있으며, LangChain과 같은 프레임워크 (framework)와 결합하여 활용도를 높일 수 있다.
미세조정의 가장 큰 장점은 모델이 특정 데이터에 깊이 최적화되어 높은 정확도와 특정 문체 (style)를 반영한 답변을 제공할 수 있다는 점이다. 또한, 지속적인 데이터 업데이트를 통해 모델의 지식을 확장할 수 있으며, 학습된 모델은 오프라인 (offline) 환경에서도 독립적으로 사용 가능하다. 그러나 파인튜닝은 고사양의 GPU와 상당한 연산 자원을 요구하며, 모델의 모든 가중치를 재학습해야 하므로 훈련 시간이 길다는 단점이 있다.
검색 증강 생성 방식 (RAG): 실시간 정보 검색을 통한 유연한 답변 생성
검색 증강 생성 (Retrieval-Augmented Generation, RAG)은 기존의 대규모 언어 모델 (LLM)을 그대로 사용하면서, 사용자의 질문에 대한 답변을 생성하기 전에 외부 데이터 소스에서 관련 정보를 실시간으로 검색하여 LLM에 제공하는 방식이다. 이는 마치 기존의 지식을 바탕으로 하는 전문가가 최신 정보나 특정 분야의 상세한 내용을 즉석에서 찾아보고 이를 참고하여 답변을 구성하는 것과 유사하다. RAG는 LLM 자체를 수정하지 않기 때문에, 최신 정보나 자주 변경되는 데이터를 즉시 반영해야 하는 시나리오에 특히 효과적이다.
검색 증강 생성 방식의 주요 단계는 다음과 같다.
첫째, 파인튜닝과 마찬가지로 BeautifulSoup, Scrapy 등을 활용하여 특정 웹사이트에서 데이터를 크롤링하고 정제한다. 이 데이터는 FAISS, ChromaDB, Weaviate 와 같은 벡터 데이터베이스 (Vector Database, Vector DB)에 저장된다.
둘째, sentence-transformers, OpenAI Embeddings 등을 사용하여 크롤링된 문서들을 벡터 임베딩 (vector embedding)으로 변환하고, 이를 벡터 데이터베이스에 저장하여 유사한 문서를 효율적으로 검색할 수 있는 시스템을 구축한다.
셋째, LangChain (랭체인)과 같은 프레임워크의 RetrievalQA 모듈을 활용하여 LLM과 검색 시스템을 결합한다. 이를 통해 사용자의 질문이 들어오면, 먼저 벡터 데이터베이스에서 관련 문서를 검색하고, LLM은 검색된 문서를 참조하여 답변을 생성하게 된다.
넷째, 사용자의 질문에 따라 실시간으로 문서를 검색하고, LLM이 해당 문서를 참고하여 답변을 생성하는 과정을 반복한다.
RAG의 가장 큰 장점은 모델을 재학습할 필요가 없으므로 구현 시간이 매우 빠르고, 최신 데이터를 쉽게 반영할 수 있다는 점이다. 또한, 파인튜닝에 비해 훨씬 적은 연산 자원 (CPU만으로도 운영 가능)으로도 운영이 가능하다는 이점이 있다. 그러나 RAG는 검색 시스템 구축이 필수적이며, LLM이 특정 데이터에 최적화되지 않고 외부 정보를 참조하는 방식이기 때문에, 파인튜닝만큼 모델 자체의 응답 정확도나 문체 일관성을 보장하기 어렵다는 단점이 있다.
FT와 RAG의 비교 및 적용 예시
파인튜닝과 RAG는 대규모 언어 모델 (LLM)을 특정 목적에 맞게 맞춤화하는 데 사용될 수 있는 강력한 도구이지만, 각각 다른 특성과 요구 사항을 가진다. 아래 표는 두 방식의 주요 차이점을 요약한 것이다.
| 구분 | 모델 수정 필요 | 최신성 유지 용이성 | 연산 자원 요구량 | 구현 난이도 |
| 파인튜닝 | ✅ 필요 | ❌ 어려움 | 🔥 높음 (GPU) | ⏳ 어려움 |
| RAG | ❌ 불필요 | ✅ 쉬움 | ⚡ 낮음 (CPU 가능) | 🚀 쉬움 |
빠르게 특정 사이트 데이터를 반영하고 싶다면 RAG 방식을 추천한다. 이는 모델 재학습 없이 데이터베이스만 업데이트하면 되므로, 실시간 또는 준실시간으로 최신 정보를 반영할 수 있기 때문이다. 예를 들어, 특정 기업의 최신 뉴스나 제품 정보를 LLM에 반영하고자 할 때 RAG 방식이 효과적이다. 다음은 Wikipedia (위키피디아) 크롤링 데이터를 RAG 방식으로 활용하는 예시 코드이다.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 데이터 로드
loader = TextLoader("wikipedia_text.txt") # 예시: 위키피디아에서 크롤링한 텍스트 파일
documents = loader.load()
# 벡터 임베딩 생성
embeddings = OpenAIEmbeddings()
vector_db = FAISS.from_documents(documents, embeddings)
# LLM + 검색 시스템 결합
qa_chain = RetrievalQA.from_chain_type(llm=OpenAI(), retriever=vector_db.as_retriever())
# 질문 실행
query = "What is Machine Learning?"
answer = qa_chain.run(query)
print(answer)반면, 높은 정확도를 요구하거나 특정 문체 (style)로 답변하게 하려면 파인튜닝을 추천한다. 예를 들어, 기업 내부의 복잡한 기술 문서나 고객 서비스 매뉴얼을 LLM이 정확하고 일관된 방식으로 응답하게 하려면 파인튜닝이 더 적합하다. 이는 LLM 자체가 해당 도메인의 지식과 특성을 내재화하도록 학습되기 때문이다. 다음은 Wikipedia (위키피디아) 페이지에서 데이터를 크롤링하는 예시 코드이다. 이 코드는 파인튜닝을 위한 데이터 준비의 첫 단계로 활용될 수 있다.
from bs4 import BeautifulSoup
import requests
# Wikipedia 페이지 크롤링
url = "https://en.wikipedia.org/wiki/Machine_learning"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 텍스트 추출
paragraphs = soup.find_all('p')
text = "\n".join([para.get_text() for para in paragraphs])
print(text[:1000]) # 일부 출력실제 적용에서는 두 방식을 혼합하여 사용하는 것도 가능하다. 예를 들어, 특정 도메인에 대한 기본적인 지식은 파인튜닝으로 모델에 내재화시키고, 최신 정보나 자주 업데이트되는 내용은 RAG를 통해 실시간으로 검색하여 답변에 반영하는 방식이다.
결론
대규모 언어 모델 (LLM)을 특정 데이터에 맞춤화하는 미세조정 (Fine-tuning)과 검색 증강 생성 (Retrieval-Augmented Generation, RAG)은 각각 고유한 장단점을 가진다. 파인튜닝은 LLM의 가중치를 직접 수정하여 모델 자체의 지식과 응답 특성을 최적화함으로써 높은 정확도와 일관된 문체를 보장하지만, 높은 연산 자원과 긴 학습 시간을 요구한다. 반면, RAG는 기존 LLM을 유지한 채 외부 데이터베이스에서 정보를 검색하여 답변을 생성하므로, 빠른 구현과 최신 정보 반영이 용이하며 낮은 연산 자원으로 운영 가능하다는 장점이 있다.
따라서 어떤 방식을 선택할지는 프로젝트의 특정 요구 사항과 사용 가능한 자원에 따라 신중하게 결정해야 한다. GPU (Graphics Processing Unit) 리소스가 충분하고 특정 데이터에 대한 최적화된 모델이 필요하다면 파인튜닝을 고려하는 것이 효과적이다. 이는 모델이 특정 도메인에 대한 깊은 이해를 바탕으로 더욱 정확하고 특화된 응답을 제공할 수 있도록 한다. 반면, 신속한 데이터 반영과 가벼운 운영이 필요하다면 RAG 방식을 적극 활용하는 것이 효과적이다. 이는 최신 정보를 즉각적으로 LLM에 반영할 수 있으며, 시스템 구축 및 운영 비용을 절감할 수 있다. 궁극적으로, 두 가지 접근 방식을 혼합하여 사용하는 하이브리드 (hybrid) 모델은 각 방식의 장점을 최대한 활용하여 더욱 강력하고 유연한 LLM 솔루션을 제공할 수 있을 것이다.