Latest Articles
-
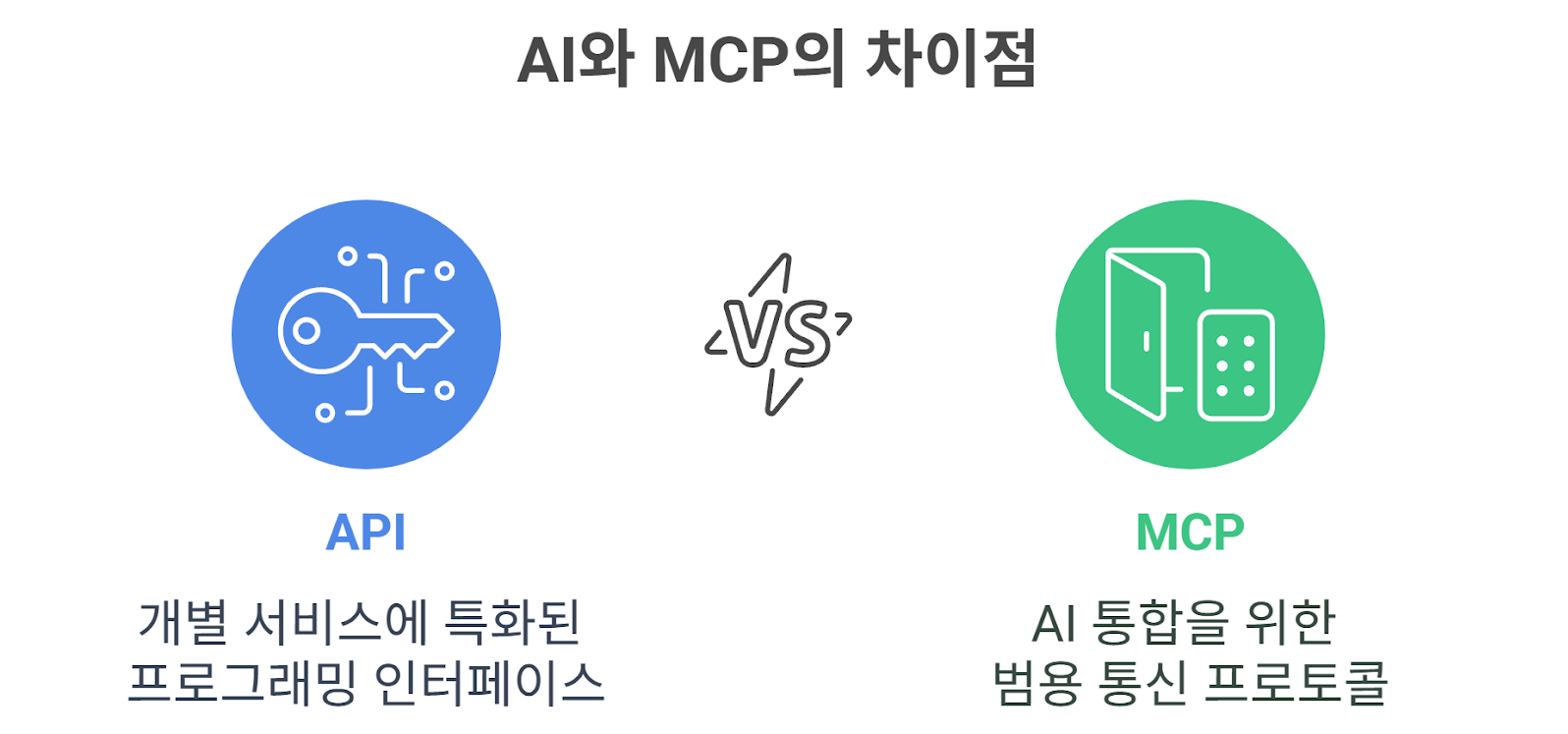 API vs MCP
API vs MCPAPI는 개발자가 요청에 따라 데이터를 가져오는 수동적 연결 방식인 반면, MCP는 LLM이 스스로 도구를 판단하여 활용하는 능동적 방식이다. 두 프로토콜은 연결의 목적은 같지만, 중심 주체와 데이터 특성에서 차이가 있다. API는 기능 호출과 단순 데이터 전송에 중점을 두고, MCP는 문맥과 대화 흐름을 통합하여 외부 도구를 활용한다.
-
 HW: 병렬 연산 계층 구조와 CUDA 독점의 실체 (2025)
HW: 병렬 연산 계층 구조와 CUDA 독점의 실체 (2025)대규모 LLM 시대의 핵심은 병렬 연산 계층 구조와 생태계 독점성에 있으며, NVIDIA의 CUDA가 사실상 유일한 상용 표준으로 자리잡았다. 대부분의 LLM은 PyTorch와 NVIDIA CUDA에 의존하고 있으며, OpenCL과 같은 대안은 실효성이 제한적이다. 병렬 연산의 성공은 하드웨어 설계, 컴파일러, SDK, 라이브러리, 프레임워크의 통합 역량에 달려 있다. OpenCL과 FPGA는 다양한 하드웨어를 지원하지만, LLM 개발에는 거의 사용되지 않는다.
-
 수식 문서 작성용 LaTeX 배포판 추천
수식 문서 작성용 LaTeX 배포판 추천MiKTeX는 설치 용량이 작고 패키지를 자동으로 설치할 수 있어 Windows 사용자에게 적합하며, TeX Live는 모든 주요 패키지를 포함하고 높은 호환성을 제공하여 학계에서 표준으로 사용된다. 두 배포판 모두 주기적인 업데이트를 제공하며, MiKTeX는 개별 패키지 중심, TeX Live는 전체 동기화 방식으로 운영된다. 설치 방법은 MiKTeX 공식 사이트에서 파일을 다운로드하고 설치 과정 중 패키지 설치 옵션을 선택하는 것으로 이루어진다.
-
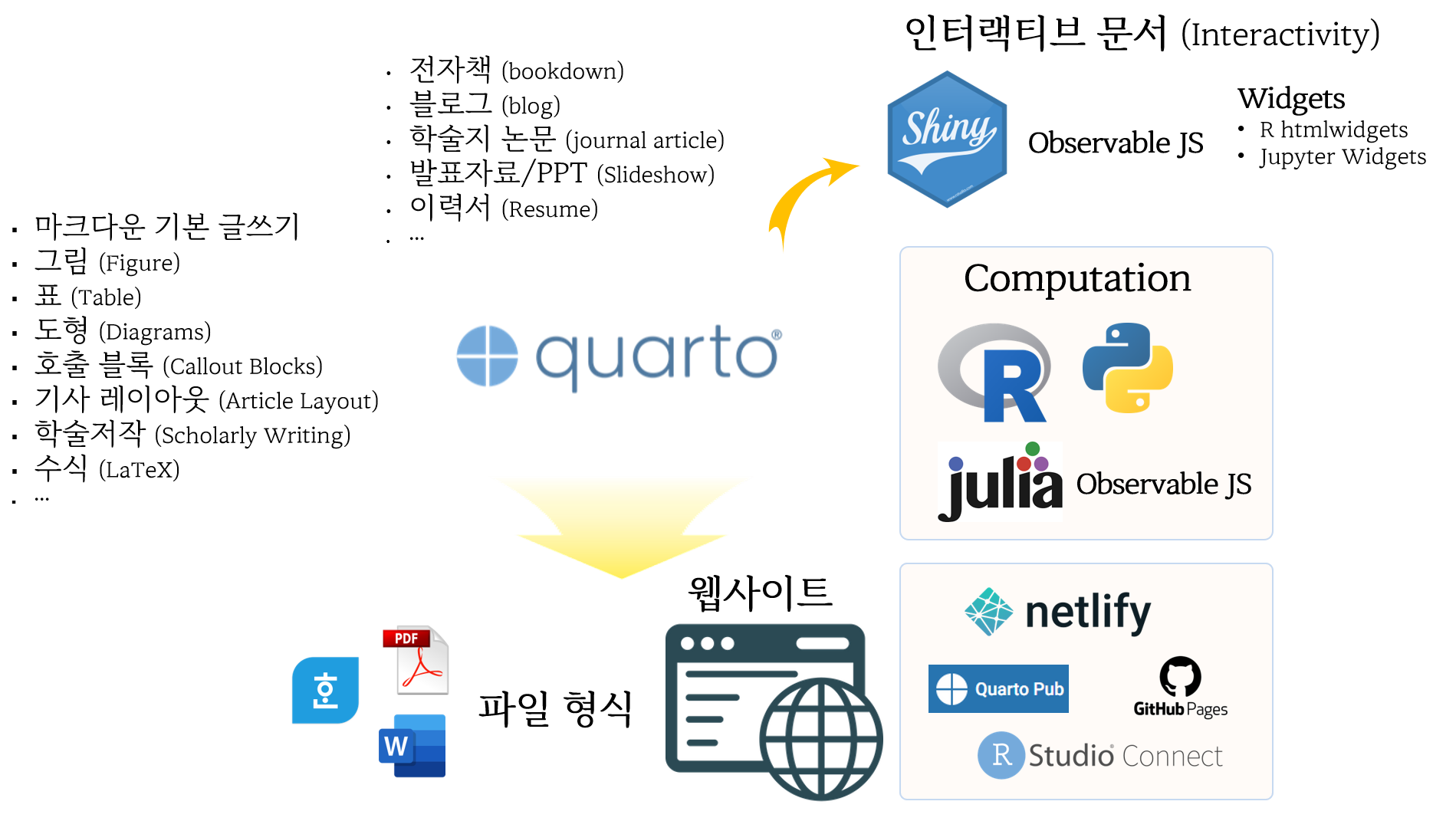 quarto: Publishing Framework
quarto: Publishing FrameworkQuarto는 Pandoc 기반의 오픈 소스 출판 시스템으로, Jupyter/R/VS Code 워크플로를 통합하여 HTML, PDF, DOCX, 슬라이드 등을 재현성 있게 생성한다. 코드 실행 및 출력 캐시, 크로스레퍼런스, 서지 인용 기능이 내장되어 있어 설정이 간편하다. Quarto는 다양한 언어와 포맷을 지원하며, 여러 도구와 비교했을 때 단일 소스에서 다양한 출력 형식을 제공하는 장점이 있다.
-
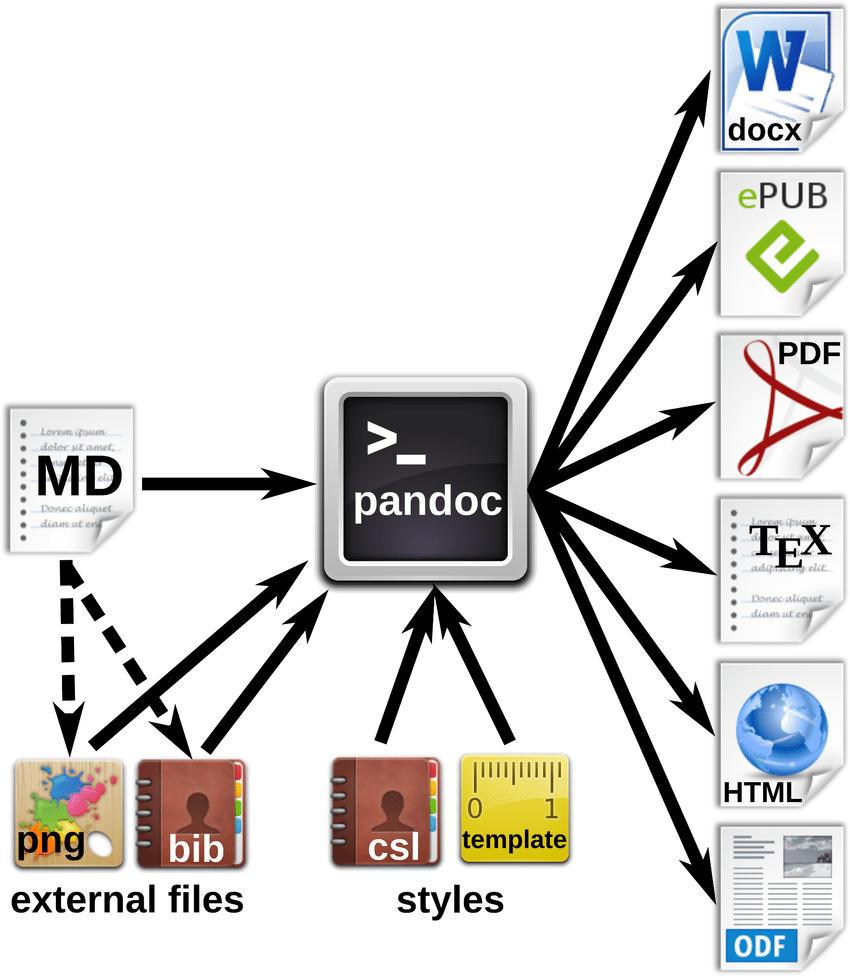 Pandoc을 이용한 파일 형식 변환법
Pandoc을 이용한 파일 형식 변환법Pandoc을 사용하여 다양한 파일 형식으로 변환하는 방법을 설명합니다. EPUB 파일은 Pandoc으로 Markdown으로 변환할 수 있으며, PDF 파일은 pdf2htmlEX와 Pandoc을 조합하여 HTML로 변환 후 Markdown으로 변환할 수 있습니다. 추가 옵션으로 LaTeX 수식을 유지하거나 PDF 내 이미지를 포함하여 변환하는 방법도 안내합니다.
-
 Database 구조 - Schema와 DB 종류
Database 구조 - Schema와 DB 종류스키마는 데이터베이스의 데이터 구조와 구성 방식을 정의하며, 데이터 무결성 유지, 타입 표준화, 관계 정의 등의 기능을 수행한다. 데이터베이스 유형으로는 관계형, 문서형, 키-값, 벡터 DB가 있으며, 각 유형은 스키마 특성과 저장 방식이 다르다. 문서형 DB는 JSON/BSON 형식으로 데이터를 저장하며 유연한 구조를 제공하고, 키-값 DB는 단순한 Key-Value 쌍으로 빠른 조회 성능을 자랑한다. 벡터 DB는 임베딩 벡터 기반의 유사도 검색을 지원한다.
-
 Claude, Gemini, Copilot, Cursor 등등
Claude, Gemini, Copilot, Cursor 등등VS Code와 Gemini Code Assist, Gemini CLI의 조합은 저비용으로 Cursor AI와 Claude Code의 기능을 대체할 수 있으며, 다양한 언어 지원과 통합성이 강점이다. 역사적으로 Microsoft의 VS Code 출시 이후 AI 코드 제안 트렌드가 시작되었고, 2025년에는 Gemini CLI와 Code Assist Extension이 Cursor + Claude 조합의 대안으로 자리잡았다. Claude Code는 개발자를 위한 CLI 도구이며, Claude Cowork는 비개발자를 위한 GUI 버전으로, 다양한 자동화 작업을 지원한다.
-
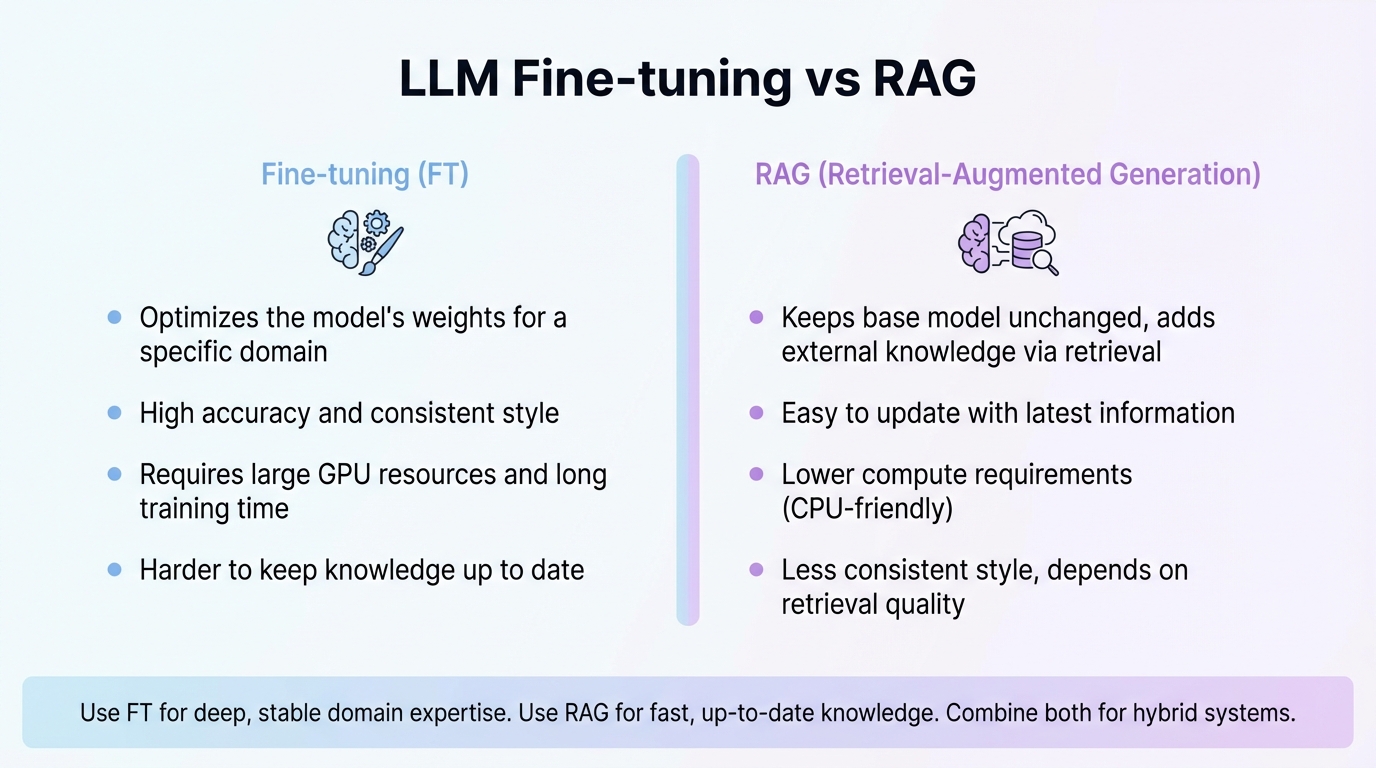 LLM Fine-tuning vs RAG
LLM Fine-tuning vs RAG대규모 언어 모델(LLM)의 미세조정(Fine-tuning)과 검색 증강 생성(RAG) 방식은 각각의 장단점이 있다. 미세조정은 특정 데이터에 대한 높은 정확도와 일관된 문체를 제공하지만, 높은 연산 자원과 긴 학습 시간을 요구한다. 반면, RAG는 외부 데이터베이스에서 정보를 실시간으로 검색하여 빠른 구현과 최신 정보 반영이 용이하며 낮은 연산 자원으로 운영 가능하다. 프로젝트의 요구 사항에 따라 적절한 방식을 선택해야 하며, 두 방식을 혼합하여 사용하는 하이브리드 모델도 효과적이다.
-
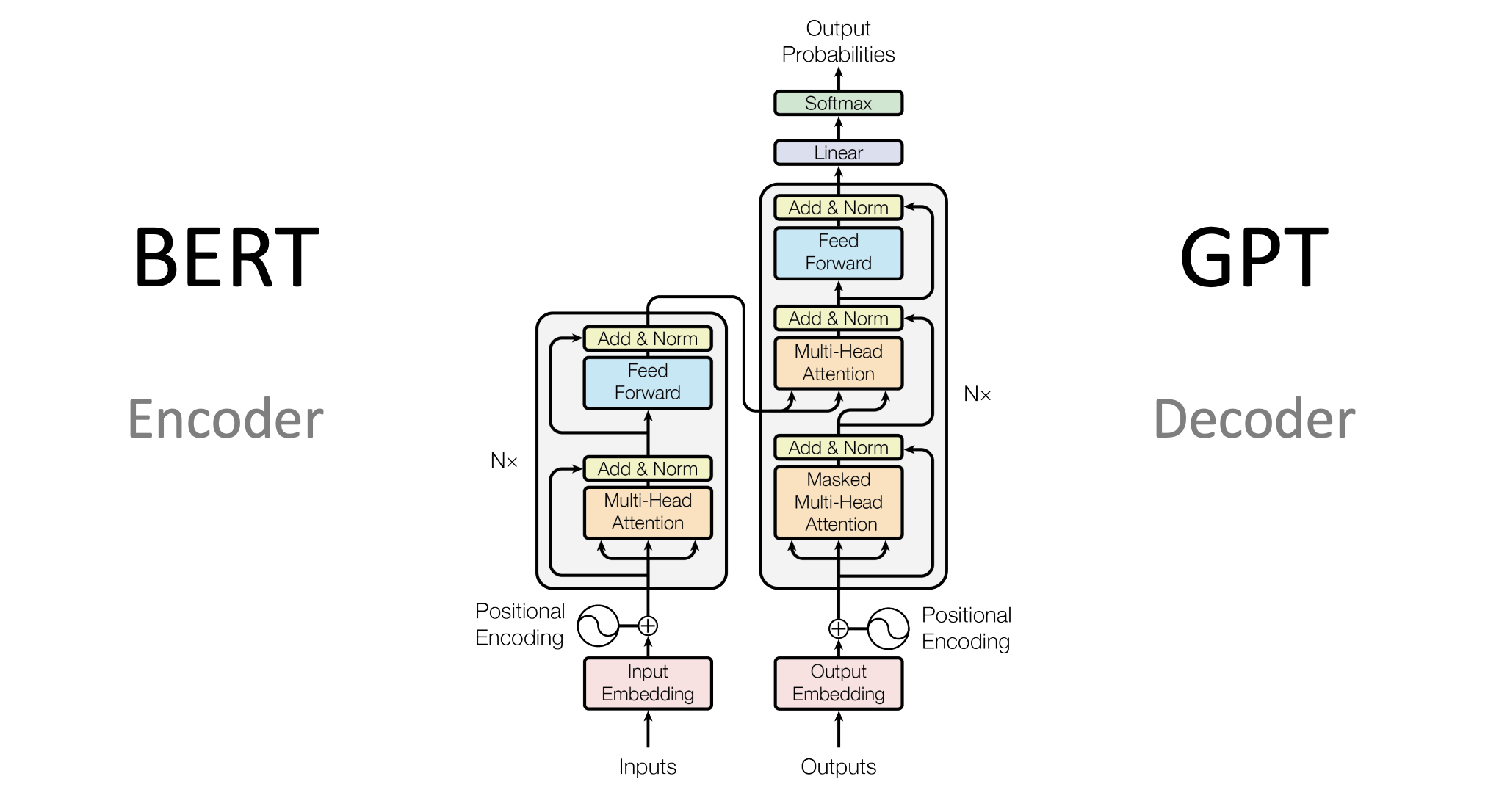 LLM 차이점을 만드는 핵심요소
LLM 차이점을 만드는 핵심요소최신 대규모 언어 모델(LLM)의 성능은 입력 데이터의 품질, Transformer 아키텍처의 유형, 학습 방식, 추론 최적화 기법에 따라 달라진다. LLM은 문장 생성, 번역, 요약 등 다양한 자연어 처리 태스크를 수행하며, 입력 데이터의 토큰화 방식, Fine-tuning 전략, 강화 학습 적용 여부가 중요한 요소로 작용한다. 각 모델은 이러한 요소들의 조합에 따라 고유한 강점과 사용 시나리오를 가지게 된다.
-
 LLM 비교 Testing Lab
LLM 비교 Testing Lab대규모 언어 모델(LLM)은 Proprietary LLM과 Open-Source LLM으로 구분되며, 각각의 장단점이 있다. Proprietary LLM은 강력한 성능과 API를 제공하지만 데이터 프라이버시에서 제약이 있으며, Open LLM은 로컬 실행과 완전한 Fine-tuning이 가능해 연구와 데이터 보호에 유리하다. LLM Testing Lab은 다양한 모델을 비교하고 평가하여 최적의 선택을 돕는 통합 실험실로, 사용자와 개발자가 신뢰할 수 있는 AI 솔루션을 설계하는 데 필수적인 도구이다.
- LLM Fine-tuning (LoRA 방식) 실습
대규모 언어 모델(LLM)을 LoRA 방식으로 미세 조정하는 방법을 안내하며, 사전 학습 모델과 토크나이저 불러오기, 학습 데이터셋 준비, 모델 경량화, Trainer 설정 및 Fine-tuning 실행, 모델 저장, Ollama 실행용 모델 변환, 로컬 실행 예시를 포함합니다. 이를 통해 다양한 오픈소스 LLM을 효율적으로 배포할 수 있습니다.
-
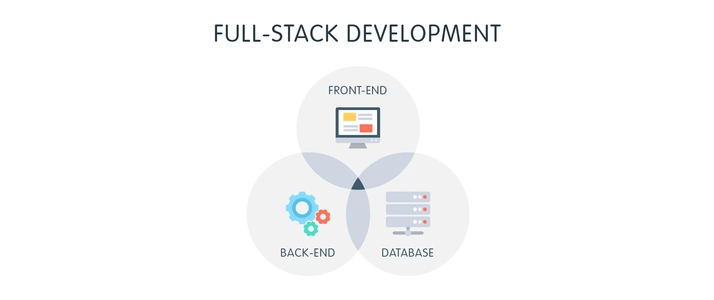 Web App Full Stack 개발 기초
Web App Full Stack 개발 기초프론트엔드는 사용자 인터페이스(UI)를 구축하며, HTML, CSS, JavaScript가 주요 언어로 사용된다. 백엔드는 데이터 처리와 서버 로직을 담당하며, Node.js, Python, Java, PHP, C# 등의 언어가 사용된다. API를 통해 프론트엔드와 백엔드 간의 데이터 통신이 이루어지며, RESTful API와 GraphQL이 주요 기술이다. 각 언어별로 다양한 프레임워크가 존재하여 개발 생산성을 높인다.
-
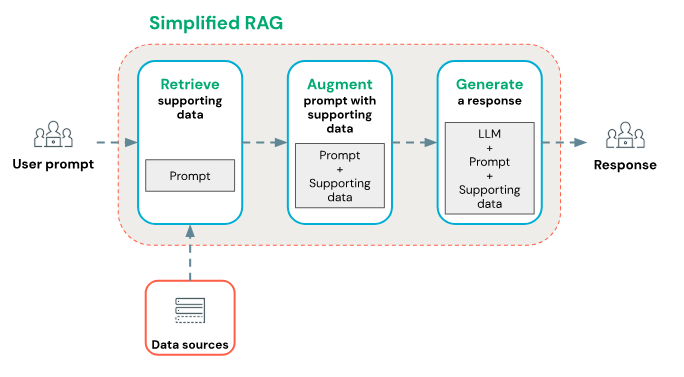 LLM에 RAG 기술 더하기
LLM에 RAG 기술 더하기대규모 언어 모델(LLM)과 RAG(검색 기반 생성) 기술의 결합은 응답 품질을 높이고 활용 범위를 확장합니다. RAG의 핵심 처리 흐름은 문서 불러오기, 청크 분할, 임베딩, 벡터 저장소, 검색, LLM을 통한 응답 생성으로 구성됩니다. LlamaIndex와 LangChain은 각각의 목적에 따라 선택할 수 있는 두 가지 주요 오픈소스 프레임워크로, 초보자는 LlamaIndex로 시작하여 기본 구조를 익힌 후 LangChain으로 복잡한 워크플로우를 확장하는 것이 추천됩니다.
-
 data structure: Notion vs Obsidian
data structure: Notion vs ObsidianNotion은 데이터베이스를 CSV 형식으로 내보내고, Markdown 파일로 내용을 저장하며, 다양한 형식의 파일을 가져올 수 있다. Obsidian은 플랫 파일 시스템을 사용하여 모든 파일을 Markdown 형식으로 저장하고, 여러 커뮤니티 플러그인을 통해 대량 데이터 관리를 지원한다. 효율적인 데이터 수집 및 정리를 위해 CSV 형식의 지시사항을 LLM에 입력하고, Obsidian에서 템플릿을 사용해 md 파일로 저장할 수 있다.
-
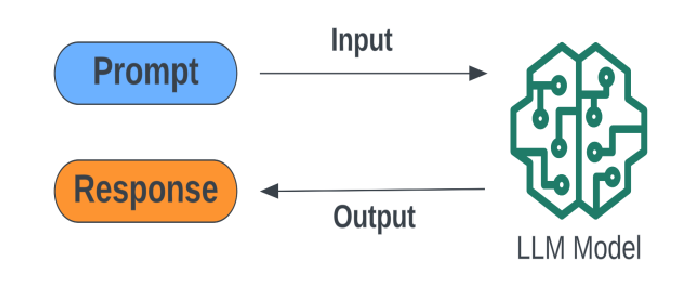 prompt: AI Prompt Engineering? 좋은 질문
prompt: AI Prompt Engineering? 좋은 질문AI 시대에 경쟁력을 갖추기 위해서는 좋은 질문을 하는 능력이 중요하며, 이는 프롬프트 엔지니어링과 밀접한 관련이 있다. 효과적인 질문은 명확성, 구체성, 현실성, 창의성을 포함해야 하며, 예시를 통해 안 좋은 질문과 좋은 질문의 차이를 설명한다. 예를 들어, 원주율의 중요성을 탐구하는 질문은 깊은 사고를 유도하고 실생활의 활용 사례를 제시해야 한다.
-
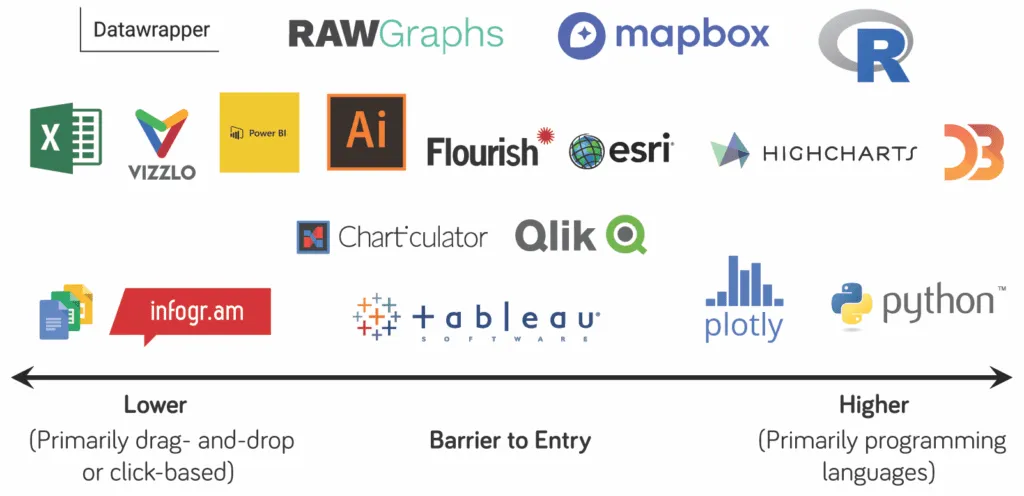 정량·정성 데이터 시각화 도구 추천
정량·정성 데이터 시각화 도구 추천정량적 데이터 시각화 도구로는 Sheet/Excel, Flourish/Tableau, Plotly, ECharts가 있으며, 각각의 라이선스, 작성 방식, 학습 난이도, 추천 사용자, 시각화 유형, 상호작용 정도가 다릅니다. 정성적 데이터 시각화 도구로는 Napkin.ai, LLM Canvas/Mindmap, Mermaid가 있으며, 이들 또한 작성 방식, 학습 난이도, 추천 사용자, 주요 용도, 출력 포맷에서 차이를 보입니다.
- HW: 반도체 원리, 분류, 파운드리시장
반도체는 디지털 전자기기의 핵심 요소로, 전기적 특성에 따라 도체와 부도체 사이의 특성을 지닌다. 반도체는 메모리 반도체와 비메모리 반도체로 분류되며, 각각 데이터 저장 및 처리 기능을 수행한다. 메모리 반도체에는 NAND Flash, NOR Flash, DRAM, SRAM이 포함되고, 비메모리 반도체에는 CPU, GPU, TPU가 있다. 반도체 패키징은 칩을 보호하고 외부와 연결하며, 이종 집적 기술이 주목받고 있다. AI 처리에 특화된 반도체가 인기를 끌고 있으며, 삼성전자와 SK하이닉스가 메모리 반도체 시장을 주도하고 있다.
- 예시 코딩 - 평균효용 극대화 이론
평균 효용 극대화 이론은 불확실한 결과값에서 정량적 효용의 기대값을 계산하고, 위험 회피 성향에 따라 확실한 결과값을 산출하는 이론이다. CRRA 효용함수를 사용하여 기대효용과 위험 프리미엄을 계산하는 방법을 구현하는 파이썬 코드 예시가 포함되어 있다.
- 예시 차트 - QQ Plot
QQ Plot은 서로 다른 변수 x와 y의 분위수로 그린 그래프이며, 두 분포의 모양이 같은지와 통계적 x 분포가 이론적 정규분포와 유사한지를 판단하는 데 사용됩니다. x축은 이론적 정규분포의 백분위수 값, y축은 경험적 히스토그램의 백분위수 값을 나타냅니다.
- 예시 코딩 - Linear Model with Panel Data
패널 데이터 분석을 위한 선형 모델을 다루며, 기업의 투자 금액에 대한 비교를 포함합니다. 랜덤 효과 모델과 고정 효과 모델을 사용하여 현금 흐름과 토빈의 q가 투자에 미치는 영향을 분석합니다. 하우스만 검정을 통해 모델 선택을 결정하고, 클러스터 표준 오차를 사용하여 잔차의 의존성을 처리하는 방법도 설명합니다.