실습·구현
-
 실습 Shell Script: 추상계층 조합 계산
실습 Shell Script: 추상계층 조합 계산2×2 행렬의 역행렬을 계산하기 위한 방법을 설명하며, BIOS/UEFI 부팅 과정, Edge 브라우저의 JavaScript 사용법, WSL2와 Ubuntu에서 C 코드를 이용한 계산 방법을 포함한다. 각 방법에 대한 코드 예제와 실행 절차도 제공된다.
-
 IDE: Cloud-based. Colab
IDE: Cloud-based. ColabGoogle Colab은 클라우드 기반의 Python 중심 Jupyter Notebook 환경으로, 데이터 과학 및 머신러닝 실험에 적합하다. 주요 특징으로는 코드와 설명을 통합 처리하는 Notebook 문서 기반 실행, 무료 계정에서도 GPU 및 TPU 사용 가능, 환경 복원 가능성, 실시간 협업 기능이 있다. 클라우드 기반 IDE는 웹 브라우저를 통해 접근 가능하며, GitHub Codespaces, Codeanywhere, CodeSandbox 등 다양한 대안이 존재한다.
-
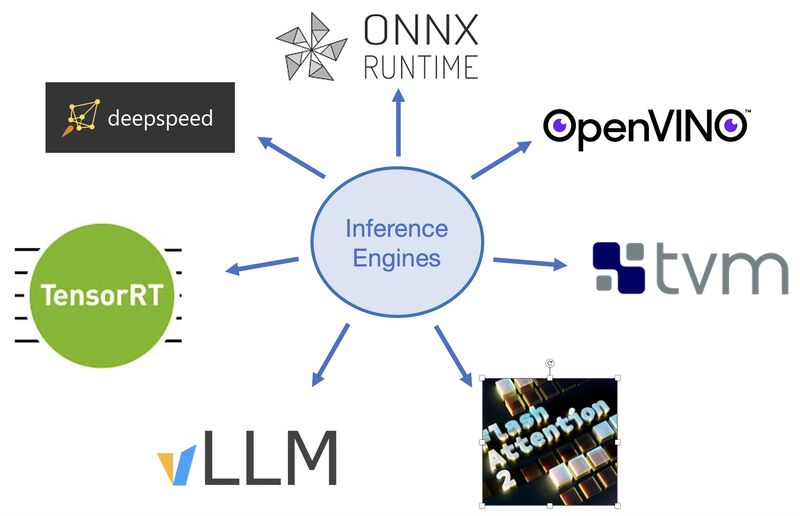 LLM 추론 엔진
LLM 추론 엔진대규모 언어 모델(LLM)을 구동하기 위한 LLM 추론 엔진은 메모리 로드, 계산 수행, 결과 생성 과정을 관리한다. LLM 추론 엔진은 PyTorch 기반, vLLM 기반, Ollama C++ 기반의 세 가지 주요 계열로 나뉘며, 각각 연구 개발, 대규모 처리, 제한된 리소스 환경에 최적화되어 있다. PyTorch는 유연한 개발을 지원하고, vLLM은 고속 처리에 적합하며, Ollama는 경량화된 모델 실행에 특화되어 있다.
-
 IDE 환경 구성 - VScode + Python + secrets + venv + GitHub 연동
IDE 환경 구성 - VScode + Python + secrets + venv + GitHub 연동Windows OS와 VS Code 환경에서 Python 프로젝트를 설정하는 방법을 설명하며, API 키는 secrets.env에 저장하고 venv로 라이브러리를 관리합니다. GitHub와 연동하여 버전 관리를 수행하고, 자동 동기화 기능을 활용합니다. 프로젝트 구조와 초기화, 패키지 설치 및 목록 저장, .gitignore 설정, Git 초기화 및 원격 연결 방법도 포함되어 있습니다.
-
 데이터 수집 및 자동화 도구들
데이터 수집 및 자동화 도구들AI 기반 데이터 분석의 프로세스는 데이터 수집, LLM 분석, 결과 저장 및 게시, 자동 반복 실행으로 구성됩니다. 자료 분석 도구는 코드 기반과 No-code/FaaS 도구로 나뉘며, 개인 실습과 빠른 프로토타이핑을 위한 추천 조합이 제시됩니다.
-
 앱 분석 - Browser-level Agentic AI
앱 분석 - Browser-level Agentic AIMaxAI, Merlin, Genspark AI의 기술 설계 구조를 분석하며, MaxAI는 다양한 LLM을 선택적으로 호출하고 웹 페이지를 조작할 수 있는 고급 AI 비서 역할을 수행한다. Merlin은 속도와 편의성을 강조한 일상용 AI 도구이며, Genspark는 복수 LLM 결과를 평가하고 결합하는 메타-LLM 구조에 강점을 가진다. Nanobrowser Chrome 확장 기능은 여러 AI 에이전트가 협력하여 복잡한 웹 작업을 수행하는 시스템을 제공한다.
- Dataset 데이터 제공 방식에 따른 데이터 수집 전략
웹페이지의 데이터 제공 방식에 따라 웹 크롤링과 웹 스크레이핑을 구분하고, 정적 페이지는 SSR로, 동적 페이지는 CSR 또는 하이브리드로 처리하는 효율적인 수집 방법을 제시한다. DevTools를 통해 구조를 식별한 후, 적절한 도구와 방법을 선택하여 최소 비용과 최대 안정성을 달성하는 것이 중요하다. 대규모 수집은 Scrapy로 파이프라인화하고, 배포는 Docker 컨테이너를 활용하는 것이 효율적이다.
-
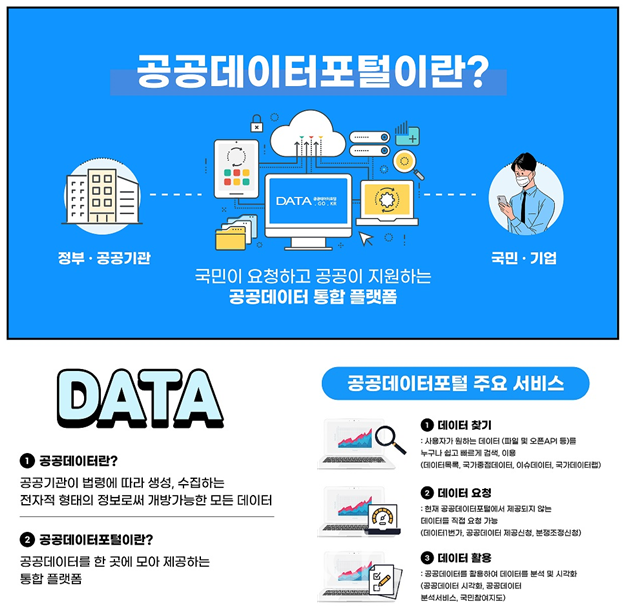 Dataset - 데이터 분석용 무료 공개 Dataset
Dataset - 데이터 분석용 무료 공개 Dataset무료 공개 데이터셋은 데이터 분석과 AI 모델 개발에 필수적이며, 포털 사이트형, 정부기관형, 학술자료형으로 나뉩니다. 포털 사이트형은 실시간 관심도 분석에 유용하고, 정부기관형은 다양한 공공 데이터를 제공하여 정책 연구와 창업 아이템 발굴에 활용됩니다. 학술자료형은 신뢰성 있는 연구 자료를 찾는 데 필수적입니다.
-
 prompt: 제품개발 시장조사 시켜보기
prompt: 제품개발 시장조사 시켜보기경쟁 제품 분석을 통해 신제품 개발을 목표로 하며, 시장 조사 및 분석, 시장 포지셔닝과 혁신 포인트 추론, 판매 전략 제안, 최종 의견 및 실행 방안을 포함한 다양한 작업을 수행한다. 주요 데이터 출처로는 한국 내 쇼핑몰과 리뷰, SNS 등이 사용된다.
- DevOps 실습 - Firebase PaaS 기반
Firebase를 사용하여 서버리스 애플리케이션을 구축하고 CI/CD를 경험하는 방법을 설명합니다. Python 코드를 Cloud Functions에 배포하고, GitHub Actions를 통해 자동 배포를 설정하며, Firebase Hosting을 통해 웹 페이지를 공개하는 과정을 단계별로 안내합니다. 필요한 도구와 파일 구조, 핵심 개념을 포함하여 로컬 개발 환경 설정 및 배포 결과 확인 방법도 다룹니다.
- DevOps 실습 - Docker Container 방식
소프트웨어 개발 초보자를 위한 Docker 실습 가이드로, Python, VSCode, Git, GitHub, Docker Desktop 및 Docker Hub 계정이 필요하다. CI/CD 개념을 통해 자동화된 빌드, 테스트, 배포 과정을 설명하며, 실습 단계로는 로컬 개발, GitHub에 코드 푸시, GitHub Actions를 통한 CI/CD 자동화, Docker 이미지 배포 및 재현성 확인이 포함된다. 핵심 파일과 폴더 구조, API 키 관리의 중요성도 강조된다.
- prompt: Engineering 기초
프롬프트 엔지니어링의 핵심 요소는 목표, 역할, 맥락, 지침, 어조, 대상 독자, 정보를 포함하여 AI에게 명확한 사고의 틀을 제공하는 것입니다. 연쇄적 사고 전략을 통해 단계별로 정보를 누적하여 분석하고, 각 단계에서 구체적인 목표와 지침을 설정하여 최적의 결과를 도출하는 방법을 설명합니다.
-
 웹 비밀정보 관리 앱 - Secret Data Manager
웹 비밀정보 관리 앱 - Secret Data Manager비밀번호 관리자와 소프트 월렛은 민감 정보를 다루며, 사용자 경험 개선을 위해 통합되고 있습니다. 두 프로그램은 멀티 플랫폼으로 제공되며, 비밀번호와 개인키를 안전하게 저장하고 암호화합니다. 비밀번호 관리자는 로그인 자동화에 중점을 두고, 소프트 월렛은 블록체인 트랜잭션 서명에 초점을 맞춥니다. 다양한 프로그램들이 존재하며, 각기 다른 기능과 강점을 가지고 있습니다.
-
 Dataset - LLM 학습용 corpus 목록 (2025)
Dataset - LLM 학습용 corpus 목록 (2025)2025년 LLM 학습용 데이터셋 목록에는 영어와 한국어의 대표 데이터셋이 포함되어 있으며, 각 데이터셋의 라이선스, 주체, 언어 및 특징, 내용 품질이 정리되어 있다. 영어 데이터셋으로는 English Wikipedia, Wiki-40B, CC-News 등이 있으며, 한국어 데이터셋으로는 KorQuAD, Korean Wikipedia, TED Talks 등이 있다. 각 데이터셋은 품질과 특성에 따라 분류되어 있다.
-
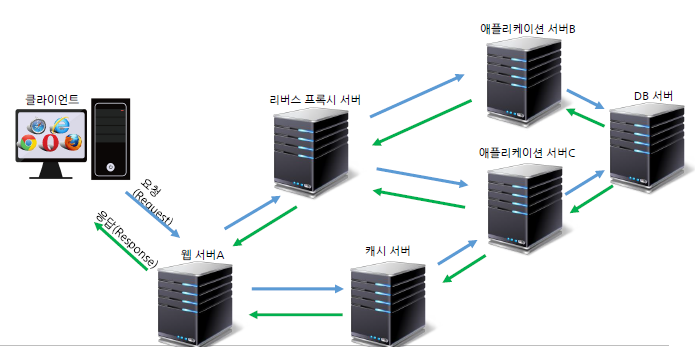 HW MiniPC: IT 서버 인프라 이해 및 실습 (일반인용)
HW MiniPC: IT 서버 인프라 이해 및 실습 (일반인용)IT 서버 인프라의 구조를 기업 조직에 비유하여 설명하며, 네트워크, 가상화, 서비스 스택의 이해를 목표로 한다. Windows와 Docker를 활용한 서비스 운영, Proxmox를 통한 Linux 기반 서버 인프라 구축, FastAPI와 데이터베이스를 Docker 컨테이너로 관리하는 방법을 다룬다. 또한, 리버스 프록시 설정과 DDNS 서비스의 필요성에 대해서도 설명한다.
-
 App 연결 시각화 및 자동화 도구 비교: Zapier, Make, n8n
App 연결 시각화 및 자동화 도구 비교: Zapier, Make, n8nZapier, Make, n8n의 자동화 도구를 비교한 결과, Zapier는 사용이 쉽고 많은 앱과 연동되지만 비용이 비쌉니다. Make는 중간 정도의 난이도로 시각적 워크플로우를 제공하며, n8n은 높은 유연성과 비용 효율성을 갖추고 있지만 기술적 지식이 필요합니다.
-
 Cloud Computing과 Web App
Cloud Computing과 Web App클라우드 컴퓨팅은 웹 애플리케이션 개발의 비효율성을 극복하기 위해 발전하였으며, 자원 낭비 문제, 높은 진입 장벽, 분산 협업 수요 증가에 대응합니다. 클라우드 기반으로 자원을 임대하여 사용하는 방식으로, 다양한 웹 애플리케이션과 개발 플랫폼이 이를 채택하고 있습니다. 장점으로는 디바이스 독립성, 초기 비용 없음, 유지보수 부담 감소, 온디맨드 확장성, 글로벌 협업 최적화가 있으며, 단점으로는 벤더 종속성, 인터넷 의존성, 보안 및 프라이버시 우려가 있습니다.
- 실습 Shell Script: LLM 실행 환경 구성
Shell은 운영체제와 상호작용하는 명령어 기반 인터페이스로, 다양한 종류가 있으며, Shell Script는 자동화된 명령어 모음 파일이다. 이 문서에서는 Ubuntu 환경에서 Bash Shell을 사용하여 LLM 실행 환경을 구성하는 방법을 설명하고, 예시 스크립트와 실행 방법을 제공한다.
-
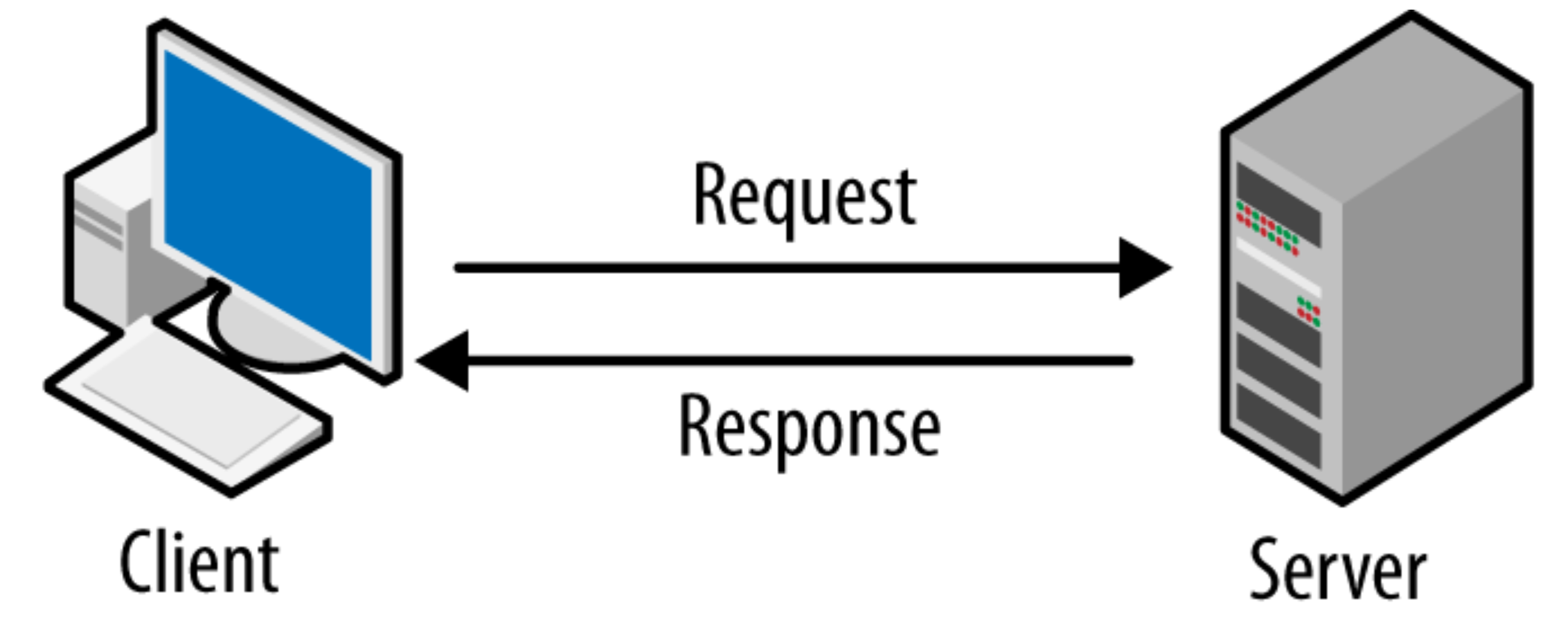 개념: Cloud computing Web App 기초 원리
개념: Cloud computing Web App 기초 원리클라이언트-서버 모델은 요청과 응답의 관계를 통해 작동하며, API, 프로토콜, 요금 구조에 기반한다. 기술의 진화는 Unix 시스템에서 클라우드 컴퓨팅으로 발전하였고, 클라우드 서비스는 IaaS, PaaS, SaaS의 계층 구조로 구성되어 있다. 각 계층은 물리적 자원, 추상화된 실행 환경, 최종 소프트웨어를 제공하며, 경제적 요소와 수요-공급 관계를 반영한다.
-
 Git: GitHub Desktop 이용
Git: GitHub Desktop 이용GitHub Desktop을 사용하여 새로운 리포지토리를 생성하고 로컬에서 작업한 후 GitHub에 업로드하는 방법과 기존 리포지토리를 클론하여 사용하는 방법을 설명합니다. 새 프로젝트는 "New Repository"를 통해 생성하고, 기존 프로젝트는 "Clone Repository"를 통해 로컬에서 수정 후 푸시합니다.