비교·선택
-
 HW: 병렬 연산 계층 구조와 CUDA 독점의 실체 (2025)
HW: 병렬 연산 계층 구조와 CUDA 독점의 실체 (2025)대규모 LLM 시대의 핵심은 병렬 연산 계층 구조와 생태계 독점성에 있으며, NVIDIA의 CUDA가 사실상 유일한 상용 표준으로 자리잡았다. 대부분의 LLM은 PyTorch와 NVIDIA CUDA에 의존하고 있으며, OpenCL과 같은 대안은 실효성이 제한적이다. 병렬 연산의 성공은 하드웨어 설계, 컴파일러, SDK, 라이브러리, 프레임워크의 통합 역량에 달려 있다. OpenCL과 FPGA는 다양한 하드웨어를 지원하지만, LLM 개발에는 거의 사용되지 않는다.
-
 Claude, Gemini, Copilot, Cursor 등등
Claude, Gemini, Copilot, Cursor 등등VS Code와 Gemini Code Assist, Gemini CLI의 조합은 저비용으로 Cursor AI와 Claude Code의 기능을 대체할 수 있으며, 다양한 언어 지원과 통합성이 강점이다. 역사적으로 Microsoft의 VS Code 출시 이후 AI 코드 제안 트렌드가 시작되었고, 2025년에는 Gemini CLI와 Code Assist Extension이 Cursor + Claude 조합의 대안으로 자리잡았다. Claude Code는 개발자를 위한 CLI 도구이며, Claude Cowork는 비개발자를 위한 GUI 버전으로, 다양한 자동화 작업을 지원한다.
-
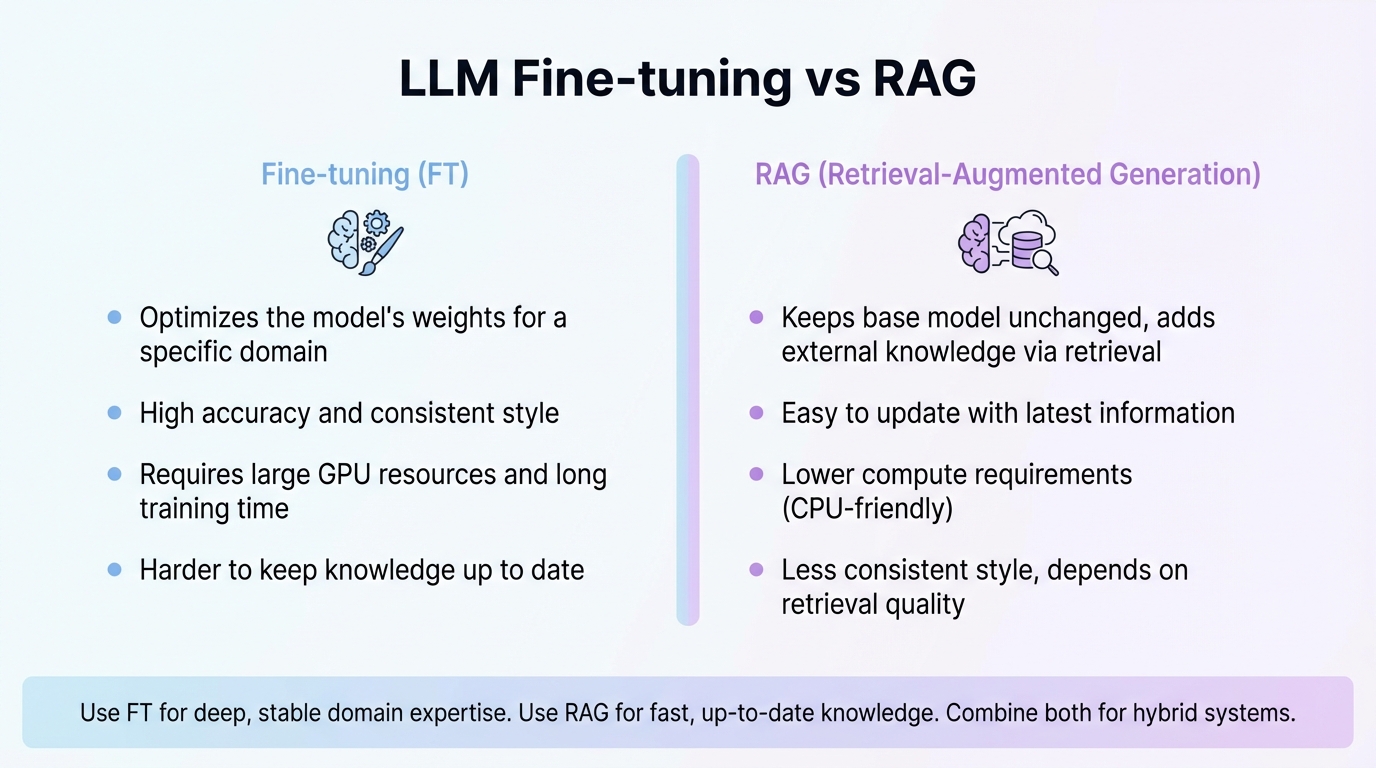 LLM Fine-tuning vs RAG
LLM Fine-tuning vs RAG대규모 언어 모델(LLM)의 미세조정(Fine-tuning)과 검색 증강 생성(RAG) 방식은 각각의 장단점이 있다. 미세조정은 특정 데이터에 대한 높은 정확도와 일관된 문체를 제공하지만, 높은 연산 자원과 긴 학습 시간을 요구한다. 반면, RAG는 외부 데이터베이스에서 정보를 실시간으로 검색하여 빠른 구현과 최신 정보 반영이 용이하며 낮은 연산 자원으로 운영 가능하다. 프로젝트의 요구 사항에 따라 적절한 방식을 선택해야 하며, 두 방식을 혼합하여 사용하는 하이브리드 모델도 효과적이다.
-
 LLM 비교 Testing Lab
LLM 비교 Testing Lab대규모 언어 모델(LLM)은 Proprietary LLM과 Open-Source LLM으로 구분되며, 각각의 장단점이 있다. Proprietary LLM은 강력한 성능과 API를 제공하지만 데이터 프라이버시에서 제약이 있으며, Open LLM은 로컬 실행과 완전한 Fine-tuning이 가능해 연구와 데이터 보호에 유리하다. LLM Testing Lab은 다양한 모델을 비교하고 평가하여 최적의 선택을 돕는 통합 실험실로, 사용자와 개발자가 신뢰할 수 있는 AI 솔루션을 설계하는 데 필수적인 도구이다.
-
 data structure: Notion vs Obsidian
data structure: Notion vs ObsidianNotion은 데이터베이스를 CSV 형식으로 내보내고, Markdown 파일로 내용을 저장하며, 다양한 형식의 파일을 가져올 수 있다. Obsidian은 플랫 파일 시스템을 사용하여 모든 파일을 Markdown 형식으로 저장하고, 여러 커뮤니티 플러그인을 통해 대량 데이터 관리를 지원한다. 효율적인 데이터 수집 및 정리를 위해 CSV 형식의 지시사항을 LLM에 입력하고, Obsidian에서 템플릿을 사용해 md 파일로 저장할 수 있다.
-
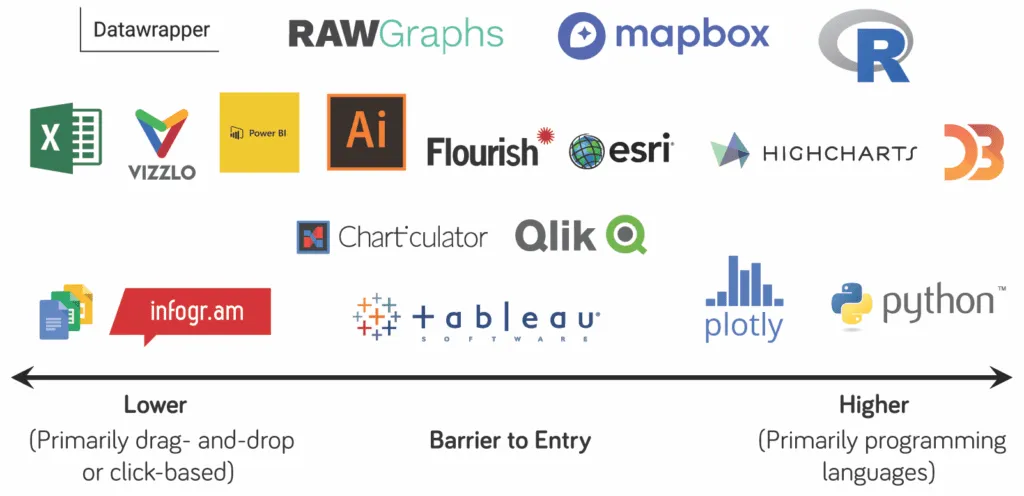 정량·정성 데이터 시각화 도구 추천
정량·정성 데이터 시각화 도구 추천정량적 데이터 시각화 도구로는 Sheet/Excel, Flourish/Tableau, Plotly, ECharts가 있으며, 각각의 라이선스, 작성 방식, 학습 난이도, 추천 사용자, 시각화 유형, 상호작용 정도가 다릅니다. 정성적 데이터 시각화 도구로는 Napkin.ai, LLM Canvas/Mindmap, Mermaid가 있으며, 이들 또한 작성 방식, 학습 난이도, 추천 사용자, 주요 용도, 출력 포맷에서 차이를 보입니다.
-
 IDE: Cloud IDE 비교 (Python 실행 환경)
IDE: Cloud IDE 비교 (Python 실행 환경)Google Colab, MS GitHub Codespaces, Amazon SageMaker Studio Lab, 및 ChatGPT Canvas의 Python 실행 환경 비교: 각 서비스의 성격, 사용자 대상, 기본 환경, 연산 자원, RAM/스토리지, 라이브러리 설치 가능성, Git 연동, 강점 및 제한 사항을 정리하여 추천 용도를 제시합니다.