Context
나는 경제학 전공 대학생 이상 수준의 독자들에게 나만의 해석을 덧붙인 교과서적 책을 집필하고 싶었다.
나의 시각에서 주류 경제학 이론을 총망라한 초안형태의 원고를 Notion DB 에 작성하고, 이를 markdown file로 export 해 두었다.
집필하려는 방대한 원고에서 새로운 통찰을 찾아내어 책의 뼈대가 되는 목차를 생성하고, 추가, 보완, 삭제 등이 필요한 부분은 수정하는 작업흐름을 AI agent를 assistant로 이용해서 구현하고 싶었다.
나는 Google AI Pro Plan (월 20불)을 구독하고 있기에, Gemini Flash Latest model 을 기본적으로 사용하고, User interface는 Gemini CLI를 사용한다. 그렇다면 나의 구독제에 할당된 AI Model Token Usage Minimization 을 하면서, wiki structure의 특징인 semantic knowledge graph (의미론적 지식 연결망)을 어떤 도구를 사용하서 어떻게 구현하면 좋을까?
아래와 같은 방법론 및 도구를 선택해 보았다.
- 추상적 workflow에 대한 개념은 Karphaty의 LLM wiki 을 사용한다.
- User interface app은 Obsidian + Terminal plugin 을 사용한다.
- AI provider platform은 Gemini CLI를 사용한다.
- Workflow 중간단계에서 knowledge graph 생성 및 활용 도구로는 Graphify 라는 python cli wrapper를 사용해 보기로 했다.
참고자료
- Harness Engineering Concept: https://github.com/forrestchang/andrej-karpathy-skills
- LLM Wiki Concept: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
- Graphify Tool: https://discuss.pytorch.kr/t/graphify-ai-knowledge-graph/9652
Response: Claude Opus 4.7 via Notion AI
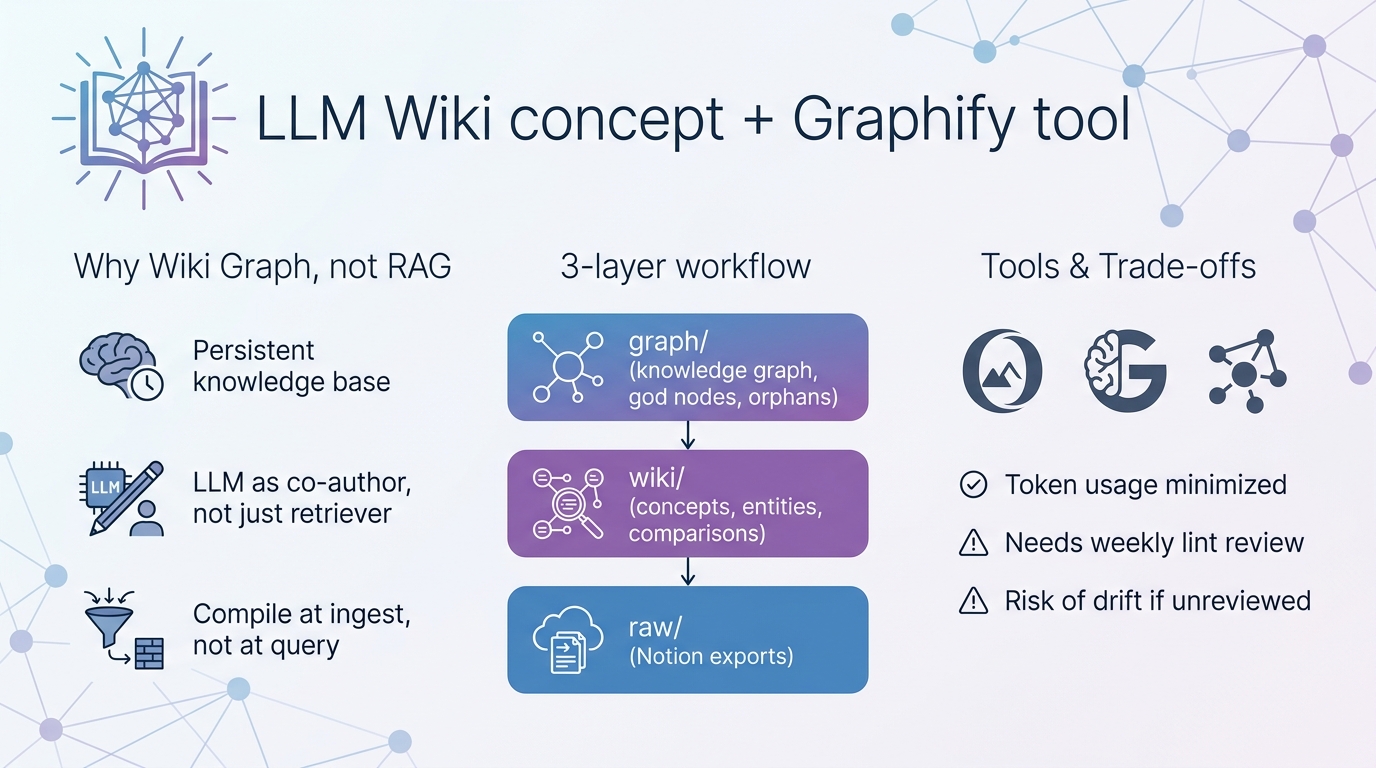
왜 RAG가 아니라 Wiki Graph였나
처음엔 Notion에서 export한 마크다운을 그대로 임베딩 인덱스에 쌓아두고 RAG로 질의할 생각이었다. 그런데 한 챕터를 다시 쓸 때마다 모델이 똑같은 문단을 다시 읽고 똑같은 요약을 다시 만든다. 대량의 토큰을 쓰고도 남는 건 단편적 답변일 뿐, “책을 쓰는” 관점에서는 아무것도 누적되지 않았다. 이 지점에서 Karpathy의 LLM Wiki gist를 읽어 봤는데, 조직 원칙은 단순했다. 지식은 query (질의) 시점이 아니라 ingest 시점에 LLM을 사용해 한 번 컴파일하고, 그 산출물을 사람이 읽을 수 있는 markdown 파일 형식으로 영속화한다. 그가 던진 “Obsidian은 IDE, LLM은 프로그래머, Wiki는 코드베이스”라는 비유가 내게는 결정적이었다. 내 경우 코드베이스에 해당하는 것이 “경제학 책의 뼈대”이고, 그것은 이미 Notion에 쓰이고 있으니 패턴이 그대로 들어맞았다. RAG는 계속 찾아다 주는 비서이고, LLM Wiki는 직접 쓰는 보조 작가다.
3계층으로 짠 Folder Structure와 Schema
시작점은 단 한 줄이었다: 원본은 절대 건드리지 않는다. raw/에는 Notion에서 export한 원고를 그대로 두고 LLM은 read-only로만 접근시켰다. wiki/는 LLM이 전적으로 소유하는 산출물 디렉터리로, index.md(카탈로그), log.md(작업 로그), concepts/(개념 페이지), entities/(인물·학파), comparisons/(비교 분석), sources/(원본 요약)으로 갈래를 나눠 둔다. 가장 중요한 파일은 GEMINI.md 스키마다. 여기에 frontmatter 규칙(type, sources, related, confidence)과 ingest·query·lint 워크플로우의 단계별 체크리스트를 박아 두니, 세션이 바뀌어도 Gemini가 같은 규율로 위키를 정비한다. Karpathy가 말한 “Schema가 없으면 매 세션이 0에서 시작한다”는 대목은 하루 만에 체감했다. 작업흐름(workflow)도 3가지로 고정했다. ingest는 새 원고 친크를 읽어 요약·개념·비교 페이지로 퍼뜨리고, query는 index.md를 먼저 읽어 관련 페이지만 팝어 답변을 합성한다. 좋은 답변은 다시 위키 페이지로 파일링해 컴파운딩을 유지한다. 유지보수(lint)는 모순·고립 노드·누락된 개념을 주기적으로 잡아낸다.
Graphify 도구로 의미망을 자동 생성하기
직접 트리플 추출기를 짤까 잠시 고민했지만 Graphify(pip install graphifyy)가 이미 내가 원하는 것을 다 하고 있었다. graphify install --platform gemini로 Gemini CLI에 스킬을 붙이고 /graphify ./raw --obsidian --wiki를 돌리니 graph.html(브라우저에서 탐색 가능), GRAPH_REPORT.md(god node·surprising connection·다음 질문 후보), graph.json(질의 가능한 풀그래프), 그리고 Obsidian vault용 스텁 페이지까지 한 번에 떨어졌다. 인상적이었던 부분은 두 가지다. 첫째, 추출된 모든 엣지에 EXTRACTED / INFERRED / AMBIGUOUS 신뢰도 태그가 붙는다. 사람으로서 검수해야 할 que가 자동으로 생기는 셌이다. 둘째, --update로 변경 파일만 재추출하고 graphify hook install로 git 커미웨 시 자동 갱신을 걸어 두면 원고·위키·그래프 3계층이 항상 동기화된다. AST 기반 추출은 로컬이라 무료이고, 내 경우 대부분이 마크다운이라 병렬적 LLM 호출이 필요하지만, 한 번 추출해 둔 그래프는 수십 차례 재사용되므로 실질 토큰 단가는 엄청나게 낮아진다.
Gemini CLI를 “도우미”로 쓰기
토큰 최소화의 핵심은 Gemini Flash를 글쓰기 엔진이 아니라 글쓰기 도우미로 격하시키는 것이었다. ingest 단계에서는 Graphify가 만든 GRAPH_REPORT.md와 관련 wiki/index.md 항목만 컨텍스트에 넣고, 원본 원고를 통으로 보내는 일은 lint 때를 제외하고 거의 없앴다. 더 결정적인 장치는 Forrest Chang의 Karpathy 스킬에서 빌려온 네 원칙을 그대로 GEMINI.md에 박아 둔 것이다. Think Before Coding은 모호한 요청에 대해 추측하지 말고 확인을 요구하게 만들고, Simplicity First는 불필요한 스타일 재장을 막는다. Surgical Changes는 원고 편집에서 압도적으로 유용했다—“3장 서론만 다듬어 줘”라고 하면 정말 그 부분만 손대고 인접 문단은 그대로 둔다. Goal-Driven Execution은 “목차 초안을 만들어 줘” 대신 “graph.json의 상위 10개 god node를 더 세분화하면서, 고립 노드가 없도록 1장·5장 목차를 제안하라”처럼 검증 가능한 목표로 프롬프트를 재작성하게 만들었다. 이 네 원칙 하나만으로도 Gemini Flash의 출력 품질 편차가 눈에 띄게 줄었다.
써 보고 느낀 상충관계 (trade-off)
장점은 분명하다. 같은 장(chapter)을 다시 다룰 때 모델이 “기억”하는 듯한 일관성이 생기고, 그래프 뷰에서 고립 노드를 보면 어떤 개념이 빠졌는지가 한눈에 들어온다. lint로 자신의 모순을 자동 적발해 주니 “주류 이론을 비판하다 자기 모순에 빠지는” 함정도 줄었다. 토큰 사용량도 무차별 RAG 대비 한 자릿수 배수 이상 줄어 Google AI Pro Plan 할당량 안에서 충분히 운용된다. 그러나 단점도 만만치 않다. 첫째, 위키는 파생 산출물이라 이른바 drift 문제가 있다. 한 번 잘못 입력된 해석이 후속 답변의 전제가 되면 오류가 복리로 부풀어 오른다. 둘째, Graphify의 텍스트 관계는 대부분 INFERRED라 사람이 검수하지 않으면 그래프가 점점 “모델이 보고 싶은 그림”으로 굳은다. 셋째, Obsidian + Terminal 조합은 desktop view에서는 뛰어나지만 mobile view에서는 그래프 탐색이 답답하다. 셋을 다 상쇄하는 루틴은 주 1회 lint 세션이다. contradiction과 orphan 보고서를 손으로 검토하는 단 30분이 사실상 이 시스템 전체의 신뢰도를 결정한다. LLM을 생성기가 아닌 검토자·연결자로 국한했을 때, 비로소 토큰 절약과 품질 향상이라는 두 목표가 동시에 달성되었다.