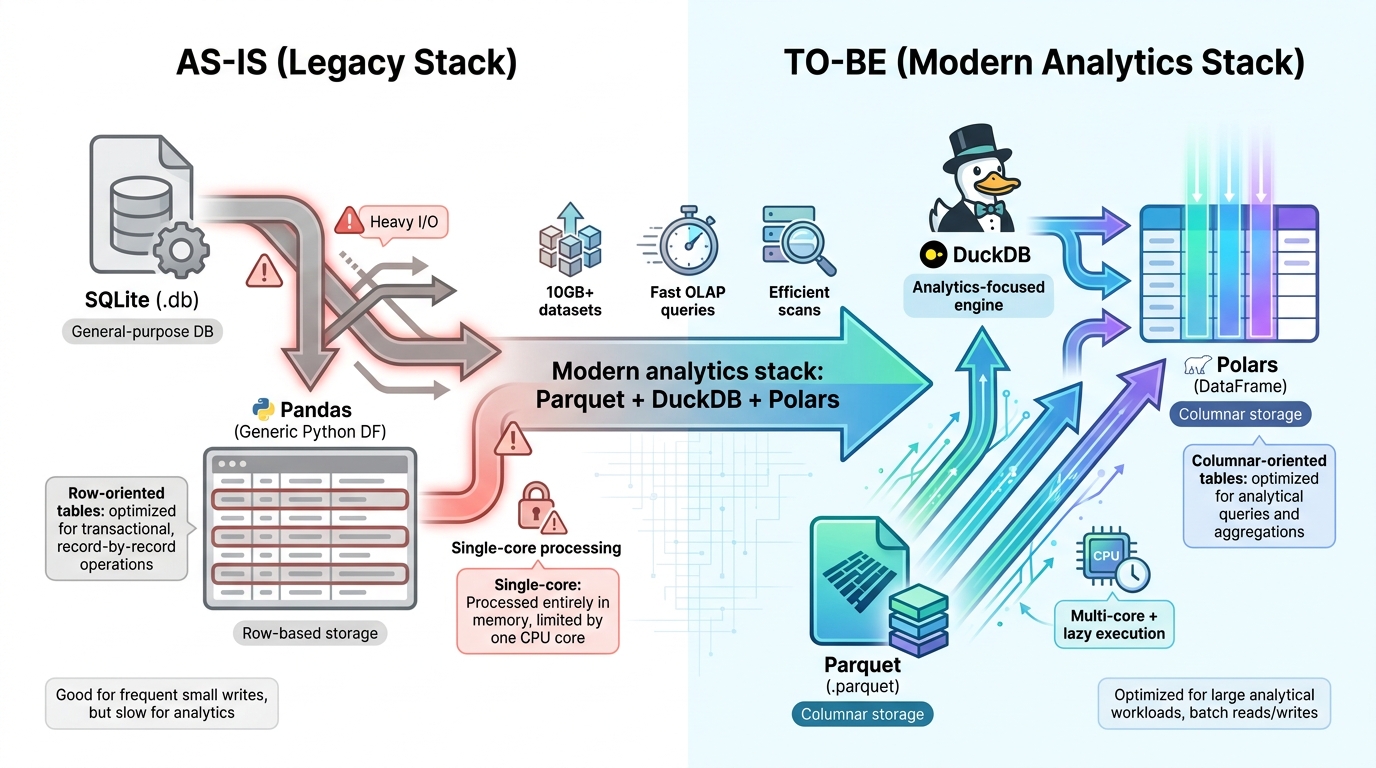
기존의 SQLite + Pandas 조합을 쓰다가 Parquet + DuckDB + Polars로 넘어가는 흐름이 요즘 데이터 쪽에서 많이 보인다. 거창하게 '모던 데이터 스택'이라고 부르기도 하는데, 막상 뜯어보면 각 도구가 맡는 역할이 명확하게 나뉘어 있어서 생각보다 진입 장벽이 높지 않다.
뭐가 뭘 대체하는 건가
| 구분 | AS-IS | TO-BE | 핵심 변화 |
| 저장 형식 | SQLite (.db) | Parquet (.parquet) | 행(Row) → 열(Columnar) 기반 |
| 분석 엔진 | SQLite3 | DuckDB | 범용 DB → 분석 전용 In-process DB |
| 데이터 처리 | Pandas | Polars | 싱글 코어 → 멀티 코어 + Lazy 실행 |
왜 바꾸는가
저장: SQLite → Parquet
SQLite 자체가 나쁜 건 아니다. 다만 분석 쿼리에서는 행 단위 저장 방식이 발목을 잡는다. SELECT revenue FROM orders 같은 쿼리를 날리면 SQLite는 관심 없는 컬럼까지 전부 디스크에서 읽어온다.
Parquet은 열 단위로 저장하기 때문에 필요한 컬럼만 골라 읽는다. 압축률도 상당히 좋고, DuckDB·Polars 모두 Parquet을 메모리에 통째로 올리지 않고 스캔하는 기능을 기본 제공한다.
분석 엔진: SQLite3 → DuckDB
"분석용 SQLite"라는 별명이 꽤 잘 어울린다. 벡터화 실행 엔진을 쓰기 때문에 OLAP성 집계 쿼리가 SQLite보다 체감상 훨씬 빠르다. 개인적으로 인상적인 부분은 유연성인데, Pandas 데이터프레임이든 Polars 데이터프레임이든 Parquet 파일이든 상관없이 SQL로 바로 질의할 수 있다. 데이터 파이프라인 중간중간에 끼워 넣기가 편하다.
처리 라이브러리: Pandas → Polars
Pandas는 오랫동안 표준이었지만, 데이터셋 크기가 커지면 메모리 문제가 슬슬 나온다. Polars는 Rust로 작성됐고 기본적으로 모든 코어를 활용한다. Lazy 실행도 지원해서, 코드를 실행하기 전에 쿼리 플랜을 최적화해준다 — 직접 신경 쓰지 않아도 불필요한 연산을 알아서 줄이는 방식이다.
무조건 좋은 건 아니다
몇 가지 상황은 짚고 넘어갈 필요가 있다.
- 트랜잭션이 잦은 워크로드: 한 줄씩
INSERT/UPDATE가 빈번하다면 SQLite가 여전히 낫다. Parquet과 DuckDB는 대량 읽기·쓰기에 최적화된 도구다. - Polars 학습 비용: Pandas 문법과 꽤 다르다.
filter(),select()같은 Expression API에 익숙해지는 데 시간이 좀 걸린다. SQL을 먼저 익힌 사람이라면 오히려 적응이 빠를 수 있다. - 에코시스템 단절: 일부 시각화 라이브러리나 ML 라이브러리가 아직 Pandas 객체만 받는 경우가 있다.
to_pandas()로 변환하면 되지만 변환 비용이 0은 아니다.
실제로 어떻게 쓰는가
세 도구의 역할을 간단하게 나누면 이렇다.
- Parquet — 원천 데이터를 저장하는 파일 형식
- DuckDB — SQL로 집계하거나 여러 파일을 합칠 때
- Polars — 데이터프레임 기반 전처리·변환이 필요할 때
10GB를 넘어가는 데이터를 다루기 시작했다면 이 전환을 진지하게 고려해볼 시점이다. 생태계 자체는 이미 충분히 성숙해 있어서 프로덕션에 투입하는 데 무리가 없다.