Top Picks (추천 도구)
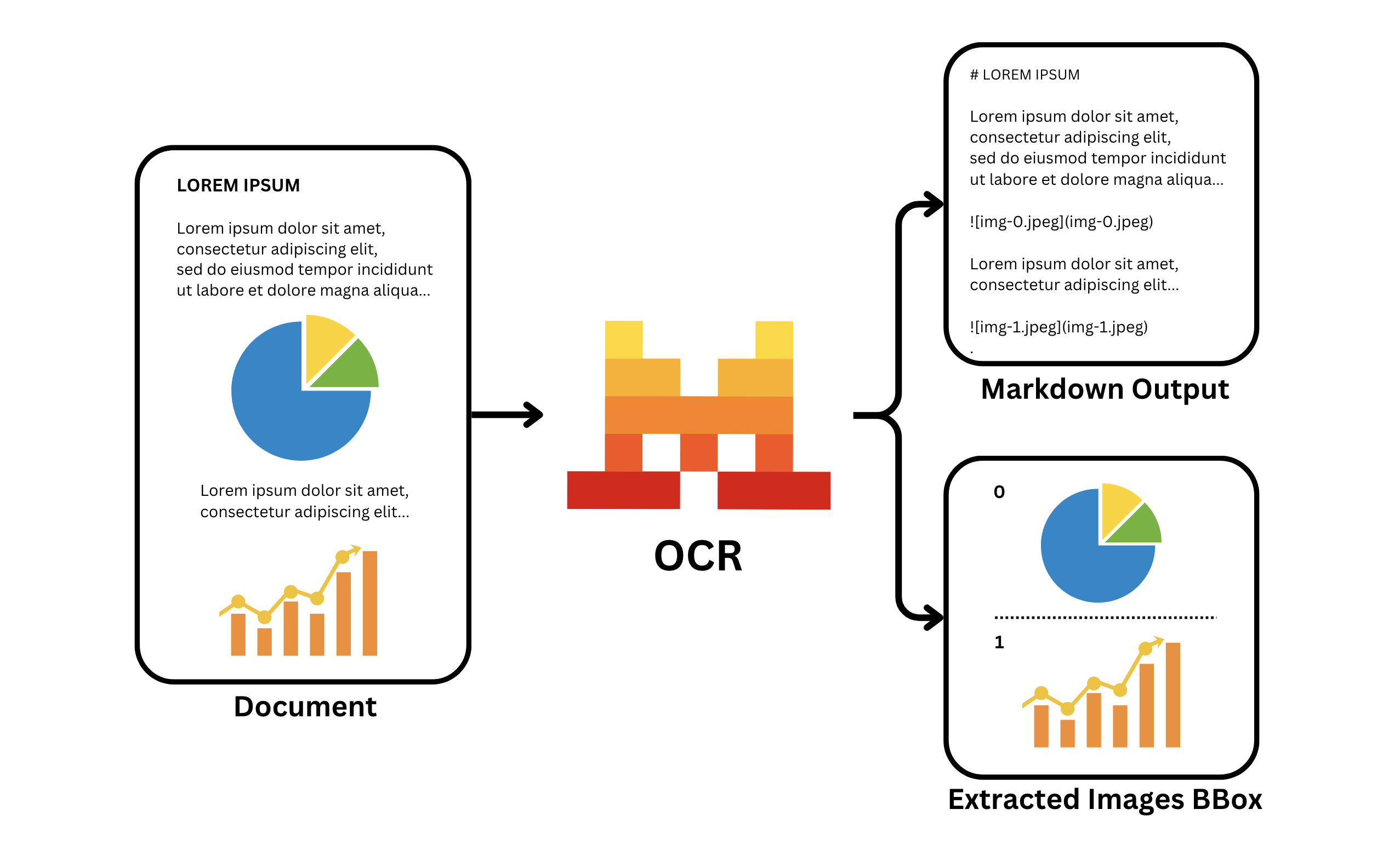
Mistral OCR
대규모 딥러닝 비전·언어 모델을 활용해 문서 구조 분석까지 가능한 고정밀 OCR API로, 처리 속도와 대용량 처리 효율이 뛰어나 기업·기관용에 적합하다.
Chronology (간단 역사)
OCR(Optical Character Recognition)은 20세기 중반 광학 패턴 인식 기술로 시작됐다. 1990년대에는 Tesseract와 같은 규칙 기반 엔진이 널리 쓰였으며, 2010년대 중반부터 딥러닝(특히 CNN+RNN 구조) 기반 OCR이 상용화되면서 이미지 품질과 언어에 관계없이 높은 인식률을 달성했다. 이후 Transformer, Vision-Language 모델의 등장으로 OCR은 단순 텍스트 인식에서 문서 레이아웃 분석, 표 구조 인식, 수식 파싱까지 확장됐다. 2023~2025년에는 Qwen2-VL, MiniCPM-o, H2OVL과 같이 오픈소스 멀티모달 모델들이 등장해 고성능 OCR을 로컬에서도 구현할 수 있게 되었고, Mistral OCR과 같은 상용 API는 초당 수천 페이지 처리와 고정밀을 제공하며 대규모 배치 환경에서 활용되고 있다.
Alternative Comparison (유사제품 비교)
| Name | Key Features | Stacks or Dependency | Pricing |
|---|---|---|---|
| Mistral OCR (Pick) | 문서 구조(텍스트·테이블·수식) 분석, 97–99% 정확도, 2,000 페이지/분 처리 | Vision-Language Transformer, API 기반 | 0.5) |
| MiniCPM-o 2.6 | 8B 경량 모델, OCRBench 최고점, 고해상도·멀티모달 | PyTorch, 로컬 GPU | 무료 |
| Qwen2-VL (7B/72B) | GPT-4급 OCRBench, DocVQA 상위권 | Transformers, Hugging Face | 무료 |
| H2OVL-Mississippi | 0.8B 소형 모델 중 OCRBench 상위, 저자원 친화적 | PyTorch, 로컬 CPU/GPU | 무료 |